|
Research article |
||||||||||||||||||||||||||||||||
|
TRAMA: Un modelo de Referencia y Arquitectura
Héctor García
Innopulse Asesores Tecnológicos C/ Aguacate 29, 2-3 E-28044 Madrid +34629613862 hgarcia@innopulse.es Jorge Morato Carlos III University of Madrid Avda. de la Universidad, 30 E-28911 Leganés, Madrid +34916248448 jmorato@inf.uc3m.es es Gonzalo Génova Fuster Carlos III University of Madrid Avda. de la Universidad, 30 E-28911 Leganés, Madrid +34916249107 ggenova@inf.uc3m.es
Resumen La trazabilidad se define en el área de Ingeniería del Software como la capacidad para rastrear la evolución y transformación de requisitos en componentes de implementación. Sin embargo, el estado actual del arte en trazabilidad no tiene en cuenta muchos elementos de información que son relevantes para el proceso de ingeniería, especialmente aquéllos creados con anterioridad al surgimiento de los requisitos. Rastrear apropiadamente estos elementos de información y el conocimiento contenido en ellos podría ser de suma utilidad para otros procesos de ingeniería en la organización. En este trabajo se describe un modelo de referencia que establece un juego de definiciones, procesos y modelos que permiten una gestión apropiada de la trazabilidad y de sus usos posteriores, en un contexto más amplio que el del desarrollo de software.
TRAMA: A Reference Model and Architecture Abstract Traceability is defined in the area of Software Engineering as the capability to track the evolution and transformation of requirements into implementation components. However, the current state of the art in traceability does not account for many information items that are relevant for the engineering process, especially those created before requirements arise. Appropriately tracing these information items and the underlying knowledge they contain could be most useful for other organizational or engineering processes. In this work we describe a reference model that establishes a set of definitions, processes and models which allow a proper management of traceability and further uses of it, in a wider context than the one related to software development.
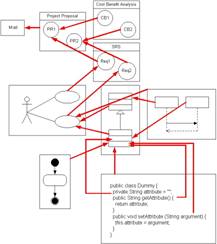
Introduction The main goal in software traceability is to trace all the information items that are considered relevant for the organization within a particular project or software product. Some classical examples of these information items are requirements, designs, source code files or test specifications and results. However, there are certain information items that are not carefully considered in current practices and literature. Emails sent by stakeholders, minutes of meetings, project proposals or cost benefit analyses are also essential documents for a software product, since they contain a great amount of knowledge that is useful for organizations (e.g. in order to manage process improvement and capability determination [20]). The capability to establish and maintain relationships between information items contained in these and other documents is essential, no matter their typology or the stage during the product life cycle in which they arise. Managing all sorts of relationships between whatever information items is what we define as total traceability. Some authors have previously discussed this term [18], although they have covered only aspects related to the engineering process. Figure 1 illustrates the concept of total traceability we discuss in this work. A software project does not start in the requirements engineering stage, as many authors [28], [33], [8], [24], [18] have pointed out. Moreover, we should not consider requirements as the core of traceability, if we adopt a wider perspective that includes information items not directly related to engineering processes, as described in [29].
In this work we claim that software traceability should be focused in establishing and managing all kinds of relationships between the information items that mediate the creation process of a software product, regardless of their type or the stage in which they first appear. None of these information items alone should be considered the core of traceability. Rather, proper traceability requires an open and decentralized network of relationships between information items. This is the reason why we entitled our reference model as TRAMA (TRAceability MAnagement), the Spanish word for “network”. Figure 1 shows a simplified case we could find in the real world. The product life cycle starts when a stakeholder sends an email asking for some kind of high level functionality to carry out a certain task. After this email, a project proposal or tender is prepared with a first approach to the problem. Later, a cost-benefit analysis is performed, determining whether the software project is viable. Then a typical life cycle follows to solve the problem, generating requirements specifications and other analysis, design and implementation artifacts such as use cases, conceptual models, sequence diagrams, statecharts and source code. In order to simplify the example, we have omitted a number of models and documents that can be considered, but in essence the main idea remains: all possible information items, documents or models are candidates for tracing purposes. Suppose now that, after carrying out the cost-benefit analysis, the project is not developed due to lack of resources. Following the current approach to traceability, in fact all those emails and documents previous to requirements specifications would not be traced, so that it would be impossible to retrieve the underlying knowledge and relationships. What if the problem is tackled again, after some time, maybe with a different approach, such as using COTS? As long as the process did not reach the requirements engineering stage, no information on the project is available, so that the project will have to start again from the beginning. On the contrary, if all those information items, previous to requirements, had been traced, the project proposal could be linked to the specifications given by vendors, and the organization could take the project up again at the same point where it was stopped. The ISO Standard for Software Life Cycle Processes [19] considers all these documents essential to software life cycle. However, other newer ISO standards on software engineering [21], [22] do not cover these aspects, and they even disregard the essential role of traceability in software development. Note that, in some sense, our work is not only related to software traceability, but also to knowledge management in the context of software development and maintenance, by focusing traceability in the knowledge that documents, models and their relationships may provide in terms of the knowledge life cycle described by Birkinshaw and Sheenan [4]. To avoid misunderstandings, in this paper we define “information item” as any piece of information related to a software product, that is put under configuration management within an organization. And we define “trace” as any kind of traceability link between information items. The TRAMA reference model assumes the context of the following four hypotheses, already discussed in [11]:
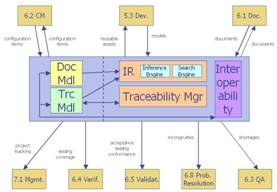
This research is based on previous works [12], [13], which have been substantially evolved regarding the TRAMA architecture and the traceability model. The rest of the paper is structured as follows: Section 2 presents the four main components of the TRAMA architecture. Section 3 explains in detail the first component, the data model. Section 4 summarizes some related works to our research. Finally, Section 5 contains the conclusions and proposals for future work. The TRAMA architectureThe basic components of the proposed architecture for traceability management systems are aimed at supporting a set of operations we enumerate later (see Table 1). We distinguish four main components in the proposed architecture: documentation and traceability data model, traceability management, information retrieval, and interoperability.
Figure 2 shows the different components of TRAMA and their relationships with other software life cycle processes [19].
Table 1 shows the relationship between architectural components and required data and operations in our traceability reference model. The required data and operations have been mainly extracted from the ISO standards ISO 15940 Software Engineering Environment Services [21] and ISO 12207 Software Lifecycle Processes [19].
Table 1. Relationships between architectural components and required data and operations
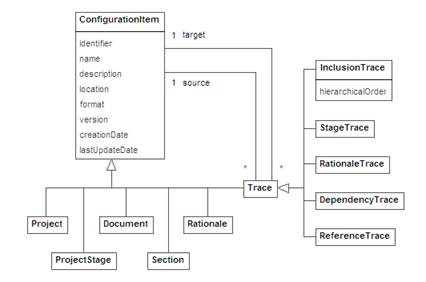
In our reference model and architecture, all elements are subject to configuration management. This includes not only information items usually considered in the literature, but also other relevant information for the goals of the organization (e.g. emails, accounting, proposals), and the traces between them. Documents and sections are also considered as configuration items in the traceability management system. In such a way we can track the evolution, versioning and replication to support software reuse. In the case a specific configuration management tool is integrated with the interoperability architectural component, configuration items can be shared between both applications. Otherwise, the traceability management system itself is in charge of configuration management features. This question affects notably to the elements considered in our model, since the information contained in traceable elements, described below, may persist in external sources, being necessary then to include references to the original locations (e.g. XPath [36] and XLink [37]). The Traceability modelIn this work we propose a data model that covers the data requirements for the TRAMA architecture. The data model pays special attention to the traces that can be established between different elements and structures. The data to be considered for each trace and information item depends on each particular implementation of the reference model. We have provided in [11] a particular implementation that meets the given requirements. Basic traceability modelFigure 3 shows a UML model for basic traceability support. The root of the data model is ConfigurationItem. A ConfigurationItem is any information item that is subject to configuration management in the organization. It has the following attributes:
The subtypes of ConfigurationItem in our data model are:
A Trace, commonly called traceability link in the literature, is the main element in the traceability system, together with ConfigurationItem. Without traces, the stored information is no more than a repository of unconnected data. Traces represent the relationships between the different items of information that are to be stored. A trace is a binary relationship established between two different information items (or elements) e1 and e2 under configuration management in a software development process. The relationship comes with some additional information m that characterizes de semantics (or meaning) of the relationship. The relationship is bidirectional, in the sense that it can be navigated two-ways. The relationship is generally asymmetrical, in the sense that the roles of the two information items cannot be exchanged while keeping the same meaning for the relationship [14], [15] (for example, if a piece of code implements a required operation, then it is not true that the required operation implements the piece of code). Therefore, a trace t can be represented as a triplet (e1, e2, m). In our data model, e1 is the source ConfigurationItem and e2 is the target ConfigurationItem associated with Trace. The semantics m of the trace is given by the trace subtype, together with the data in the attributes it inherits from ConfigurationItem. Being a kind of ConfigurationItem, a trace is also a candidate to be linked, through another trace, to any information item in the model. This is important in order to support version control and reuse. Each trace subtype is meant to specify a particular kind of trace between pairs of specific ConfigurationItems. We have defined five subtypes of Trace in our data model:
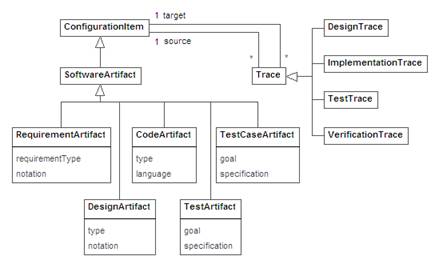
As it can be observed, each trace subtype inherits the source and target associations from the general trace. Therefore, the pairs of information items allowed in each subtype must be controlled through restrictions in the associations. This is, in our view, easier than defining the source and target associations for each subtype. Further considerations on the properties of traces have been extensively dealt with during the definition of the reference model [11], although it is not the purpose of this paper to describe them in full. Traceability for software artifactsBasic traceability provides support for tracing rather unspecific documents and information items in a project. However, we consider software artifacts and the related traces deserve a special attention in our context. Therefore, the TRAMA data model contains a second module dealing specifically with software artifacts. Given the many different kinds of software artifacts that can be considered, we have chosen to model only some of the most common artifacts (see Figure 4). This will be enough for the majority of purposes. In any case, flexibility and scalability can be achieved through convenient extensions by means of inheritance, to meet the particular needs of an organization.
We have defined five subtypes of SoftwareArtifact in our data model:
All software artifacts in TRAMA can play the source role in the five basic trace subtypes, and they can play the target role in DependencyTrace and ReferenceTrace. Besides, we have defined four specific trace subtypes between software artifacts, allowing round trip engineering through software artifacts:
Like in the case of basic trace subtypes, the pairs of software artifacts allowed for each subtype must be controlled through restrictions in the source and target associations from Trace to ConfigurationItem. Traceability for project definition and Project SupportThe full reference model [11] contains additional information items to properly structure and trace the different elements of project documentation (e.g. document types required in a given project), and project support (e.g. tasks within project stages, related with task output documents, and stakeholders involved in a project with task assignments). They are omitted here for the sake of brevity. Related workThe usefulness of traceability in the area of Software Engineering has been argued in the literature. Processes such as change management obtain substantial benefits from traceability [10], [6]. Traceability links allow establishing relationships between different items, or knowledge assets, and they are of interest for the organizations [30]. The capability to reuse software assets, such as requirements, models or code, is also a question closely related to traceability [7], as well as it is domain and product analysis [8]. A fully fruitful management of traceability demands great efforts and costs, as described by Egyed et al. [9]. To tackle this problem, new perspectives are arising, such as Boehm’s Value Based Software Engineering [5], that focus on which elements are more relevant or require more detailed attention in order to lower the effective costs. The most popular choice when automating traceability consists in the development of systems and frameworks that clearly state the information related to traceability links, and how to implement them in a standardized manner, instead of depending on specific features provided by vendors. Sherba et al. [32] provide a traceability management system that, by using parsers, integrates different tools that share the project information items in a common repository. The main problem of this approach is to maintain this duplicated and coupled structure. In Alves-Foss et al. [3] we can find some suggestions on how to avoid this problem, together with a compromise on the granularity or detail level required in this kind of systems. Other efforts in this direction have led to establish standardized formats for documents and models, most of them based in the eXtensible Markup Language, such as XML Metadata Interchange [27]. A metamodel for traceability management and a set of processes related to software traceability, based in patterns, can be found in Kelleher [23]. Alarcón et al. [1] describe a software engineering environment considering an integrated traceability system, in which documents generated within the environment are stored in an XML compatible format. Many efforts to introduce tags within the source code to provide traceability have been described in earlier years by Guerrieri [16], too. Alves-Foss et al. [2] suggest also the use of XMI to represent UML designs, and JavaML for the source code. A set of DTDs and transformations make it feasible to translate the models into source code and vice versa. Another significant problem in traceability systems is to determine the proper information retrieval and processing subsystems. Huffman et al. [17] have applied information retrieval techniques to create automated candidate traceability link lists. Marcus et al. [26] have used latent semantic indexing to detect links between product documentation and source code, and Spanoudakis [33] has established a set of heuristic rules to analyze links between different elements that resulted in patterns to determine which candidates were valid. Regarding information items and relationships, the best analysis is the one by Ramesh and Jarke [29], where we can find a complete classification of traceability links and the data that should be considered in reference models. They suggest also to consider six dimensions regarding the knowledge that underlie each link: What?, Who?, Where?, How?, Why? and When? Different classifications providing more information and link types can be found in Maletic [25], with the goal of supporting conformance analysis and inconsistency finding. In Letelier [24] we find a model to support traceability management for UML projects, including rationales and stakeholders, as well as many software artifact types. Tryggeseth and Nitrø [34] classify relationships in different categories, keeping in mind a double structure related to application and documentation, while Riebisch [31] takes into account the link types depending on the structure of requirements documents. Von Knethen [35] establishes a difference between traces linking elements in the same abstraction level and traces between elements in different abstraction levels. Sherba et al. [32] describe some examples of links that are useful to determine some of the types of relationships between elements. Conclusions and Future WorkThe definition of traceability considering only documents and models directly related to engineering processes, in the particular field of Software Engineering, will deprive organizations from a valuable knowledge. This knowledge is the bridge from engineering procedures to the rest of the organization activities. In this work we have showed that it is feasible to reach total traceability considering any source of knowledge. We have argued that the traditional perspective of traceability, where requirements are the core and the starting point in traceability, may be wrong. On the contrary, any document, close or not to software, is a traceable information item and a valuable candidate to be considered by traceability management systems. The problems found in current approaches to traceability could be solved by introducing total traceability in the methodological definition of the software development process. The support to other organizational processes could result in decreasing the effective costs on applying traceability. Unfortunately, the ISO Standard 24744 Metamodel for Development Methodologies [22] disregards the essential role of traceability in software development, even though it tries to consider all aspects of the software development process, from documentation to tasks, as well as human resources involved. To reach such an ambitious goal, it is necessary to track any knowledge asset. This requires including under configuration management any information item that persists in time. Then, it becomes necessary to extend configuration management to all areas in the organization, not only to those directly related to engineering processes. In this sense, it is essential to establish a common framework in the organization for configuration management and traceability. The information contained in a traceability management system is useful not only for software processes, but also for other processes. Multiple uses of this information, especially through information retrieval and data mining, will result in short- and long-term benefits for organizations. It would be worthwhile to implement and introduce traceability management in the industry, as well as lowering the effort required to manage and maintain traceability-oriented repositories. We are planning to develop and particularize TRAMA, our reference model and architecture for traceability management, to better integrate it with several ISO Software Engineering standards (in particular, ISO Standard 24744 Metamodel for Development Methodologies [22]), which may require new configuration item and trace types, and/or new attributes for the already defined elements in the data model. AcknowledgementsAuthors are indebted to Manuel Bollaín, Diego Pérez and Carlos del Cuvillo because of their useful comments and suggestions during the development of this work. References
|
||||||||||||||||||||||||||||||||
| Recibido el: 04-04-2012; Aprobado el: 02-05-2012 | ||||||||||||||||||||||||||||||||
|
Técnica Administrativa |
Vol.:11 | |||||||||||||||||||||||||||||||
|
URL http://www.cyta.com.ar/ta1103/v11n3a1.htm |
||||||||||||||||||||||||||||||||