Research article
Survey de Tecnologías Grid
Sofia, Albert Osiris
Unidad Académica Río Gallegos, Universidad Nacional de la Patagonia Austral. Argentina
osofia@unpa.edu.ar
Casas, Sandra Isabel
Unidad Académica Río Gallegos, Universidad Nacional de la Patagonia Austral. Argentina
lis@uarg.unpa.edu.ar
Resumen
La grid es una tecnología emergente que se perfila como el nuevo paradigma de computación paralela y distribuida, apta para aplicaciones que requieran grandes recursos. En el proceso de definición de este modelo han surgido una enorme variedad de propuestas y herramientas para el desarrollo e implementación de grids y portales grid. El propósito de este trabajo es brindar un panorama actualizado del conocimiento sobre el tema, así como una visión unificada de las técnicas y herramientas más aceptadas actualmente, de manera que sea entendible el universo de propuestas actuales para generar nuevos proyectos.
| Palabras Clave: | Grid, Globus, e-Ciencia |
Grid Technologies Survey
Abstract
Grid is an emergent technology that is outlined as the new paradigm of parallel and distributed computation, suitable for the applications that require great resources. In the process of definition of this model, a huge variety of proposals and tools for the development and implementation of grids, and grid portals have arisen. The intention of this work is to offer an updated panorama of the knowledge on the subject. Besides, a unified vision on the most accepted techniques and tools are summarized to contribute to the generation of new projects.
| Key-words: | Grid, Globus, e-Science, Portal Grid |
1. Introducción
Los últimos años han visto el surgimiento de los Grids [2]: grupos de ordenadores, dispositivos de almacenamiento, sensores, etc., situados en ubicaciones separadas y distantes geográficamente, y conectados a través de redes públicas, que pueden ser utilizados de forma transparente desde cualquier lugar del mundo.
Gracias a los Grids, en la actualidad se pueden abordar problemas que hasta hace poco eran inabarcables, ya fuese por necesitar grandes cantidades de potencia de cálculo, grandes capacidades de almacenamiento u otros recursos escasos o únicos (telescopios, aceleradores, sensores).
Con todo, a menudo es complicado utilizar el Grid, por la necesidad de aprender varias utilidades de línea de comandos y nuevos conceptos. Por ello es necesario desarrollar entornos que permiten a un usuario utilizar fácilmente el Grid, presentando una vista atractiva, uniforme e intuitiva de los recursos que lo componen. Si bien se han realizado algunos esfuerzos para compilar las tecnologías disponibles [23], el avance de propuestas en una temática tan reciente es muy vertiginoso. El propósito de este trabajo es brindar un panorama actualizado del conocimiento sobre el tema, así como una visión unificada de las técnicas y herramientas más aceptadas actualmente, de manera que sea entendible el universo de propuestas actuales para generar nuevos proyecto.
Para ello presentaremos este Survey como se describe a continuación: en la sección 2 presentaremos un panorama del nuevo paradigma de computación denominado Grid. En la sección 3 se realiza una referencia a las principales aplicaciones que hacen uso de esta tecnología, que son las aplicaciones de e-Ciencia. En la sección 4 se presenta en forma detallada la arquitectura Grid y las principales herramientas de software. En la sección 5 se discute sobre la temática de los portales Grid y en la sección 6 se presentan las principales herramientas de desarrollo para generar este tipo de software. En la sección 7 presentamos el portal Grid SURAGrid como caso de estudio. Finalmente presentamos las referencias bibliográficas en la sección 8.
2. Grid Computing
Según uno de sus creadores, un sistema es Grid sólo si es “un sistema que coordina recursos que no están sujetos a un control centralizado, usando protocolos e interfases estándares, abiertos y de propósito general, para ofrecer una variedad de servicios no triviales” [1].
Igual que la red eléctrica permite obtener energía en cualquier lugar y de forma transparente al usuario, se pretende que los Grids computacionales permitan obtener “energía de computación” (ciclos de CPU, espacio en disco, ...) desde cualquier ubicación, utilizando para ello redes de comunicación públicas. Para esto, es necesario utilizar ciertas herramientas que cohesionen los recursos pertenecientes a uno de estos Grids, y proporcionen los mecanismos necesarios para que los usuarios puedan acceder al Grid, y para que los programadores puedan elaborar aplicaciones que sepan utilizar todos esos recursos. Estas herramientas, en muchas ocasiones, se complementan con interfaces de usuario fáciles de utilizar implementados en forma de “portales Grid”.
Del mismo modo que la disponibilidad de ordenadores potentes y baratos, junto con redes de alta velocidad, permitió la popularización de la computación distribuida, la disponibilidad y popularidad de Internet permite unir recursos computacionales distantes geográficamente para utilizarlos como si fueran un solo superordenador o conjunto de ordenadores no distantes; esto último se conoce como Grid computing [2].
El término Grid se acuñó por analogía con las redes de distribución eléctricas (en inglés: power grids), gracias a las que se puede consumir energía eléctrica de forma transparente y en cualquier lugar y en cualquier momento, independientemente de su origen o de las necesidades de otros centros de consumo.
A menudo, los recursos que se necesitan para una aplicación concreta no pueden reunirse en un mismo lugar, ya porque para su funcionamiento tienen que estar en un lugar determinado, o porque no pueden ser trasladados. Un Grid permite reunir y unificar recursos computacionales (tiempo de CPU, espacio en disco, datos procedentes de sensores, etc.) situados en ubicaciones distantes geográficamente y administrados por diversas organizaciones, de forma que quien los necesite pueda utilizarlos.
2.1. Reseña Histórica
El término “Grid” fue acuñado a mediados de los ’90 para designar una infraestructura de computación distribuida propuesta para ciencia e ingeniería avanzada. Inicialmente sólo se hizo referencia a la “necesidad de compartir recursos en forma transparente, disponibles para los usuarios a través de un ambiente de red” [3]. El término “Grid” recién comenzó a utilizarse en 1997, al gestarse el proyecto “National Technology Grid”, el que a su vez tomó como base las experiencias obtenidas en el experimento I-WAY de 1995 [4]
En 1997 comienza el desarrollo de Globus, Condor y UNICORE y se
libera SRB.
En 1998 se crea el “Global Grid Forum” (www.gridforum.org) y se publica
el libro que sienta las bases de esta nueva tecnología [2].
En 1998 se presenta Globus V1.0.
En 2002 se presenta OGSA.
A partir de entonces se han realizado muchos esfuerzos para implementar Grid en distintos ámbitos, fundamentalmente aquellos que requieren de grandes capacidades de cálculo, almacenamiento y/o utilización de recursos geográficamente dispersos.
Si bien una de las principales características de Grid es la heterogeneidad de hardware y software interconectado, el desafío fundamental actual es la definición de un estándar universal para su implementación.
Esto está relacionado además con la característica de evolución histórica de las Grid –que comparte en cierto sentido con Intenet-. Inicialmente se desarrollaron “IntraGrids” para organizaciones o aplicaciones específicas, pero con el tiempo el concepto derivó en la posibilidad de aprovechamiento mundial de esos recursos, con lo que se gestó el término “InterGrid”, “LA Grid” [5].
2.2. Principales Características
Previo a Grid existen otras tecnologías, tales como “Computación Distribuida”. Sin embargo, no todos los sistemas geográficamente dispersos son sistemas Grid. Un sistema Grid posee las siguientes características [6]:
- Escalabilidad
- Distribución Geográfica
- Heterogeneidad de hardware y software
- Compartir recursos
- Múltiples administraciones
- Coordinación de recursos
- Acceso transparente a los usuarios
- Acceso fiable, a través de la implementación de QoS
- Acceso consistente, a través de la utilización de estándares (middleware)
- Acceso permanente, a través de la recuperación ante errores
2.3. Componentes:
En cuanto a los recursos que puede ofrecer, los principales componentes de un Grid son los siguientes [7]:
Poder de cómputo
Almacenamiento
Comunicaciones
Software y Licencias de Software
Equipamientos y recursos especiales
Trabajos y Aplicaciones
Planificación, reserva y liberación de recursos
Desde el punto de vista de los componentes de software necesarios para poder diseñar e implementar una arquitectura Grid, son los siguientes:
Componentes de administración
Software de nodos
Software de envío de peticiones
Administración distribuida (jerárquica u otra)
Planificadores
Software de comunicaciones
Software de monitoreo
3. Aplicaciones. e-Ciencia
Se entiende la e-Ciencia como el conjunto de actividades científicas desarrolladas mediante el uso de recursos distribuidos accesibles a través de Internet. Hoy en día cálculo, almacenamiento e información, entre otros, constituyen los principales recursos utilizados y compartidos mediante la red. La evolución de las redes de comunicaciones de alta velocidad dedicadas a la investigación y de las tecnologías y aplicaciones colaborativas están creando un escenario idóneo para la interacción entre investigadores. Por este motivo, si bien la e-Ciencia puede llevarse a cabo de forma individual, ésta es más efectiva cuando va unida a una colaboración global.
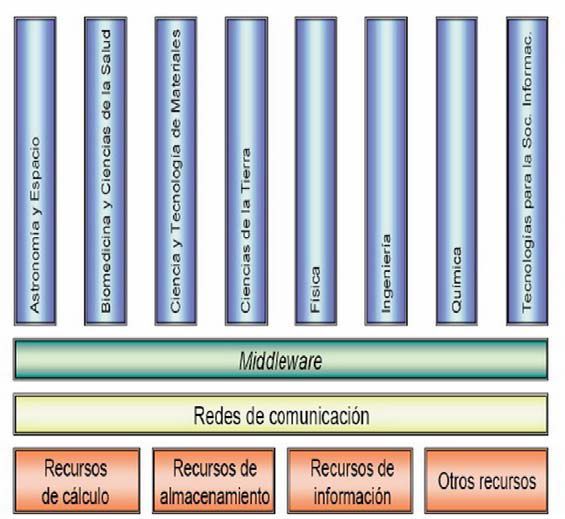 |
Fig. 1. Aplicaciones e-Ciencia |
En la taxonomía de la e-Ciencia (figura 1) se han representado tres capas horizontales que corresponden a los recursos accesibles (de cálculo, de almacenamiento, de información y otros recursos), las redes de comunicación que permiten el acceso a éstos, y el middleware o software intermediario. Esta última capa permite a las aplicaciones utilizar de forma conjunta, o coordinada, recursos disponibles en localizaciones remotas. Estas tres capas son comunes para el desarrollo de la e-Ciencia en cualquiera de las ocho áreas de investigación representadas y que, evidentemente, no son las únicas que pueden beneficiarse de la e-Ciencia.
La e-Ciencia utiliza la tecnología Grid para simplificar el acceso a los recursos y aprovechar su utilización, aunque no es el único método para conseguirlo [8]. Otras tecnologías como el telnet, el ftp o el P2P permiten también la accesibilidad a recursos distantes. Según la definición de uno de los padres del Grid, Ian Foster [1], “un Grid es un sistema que coordina recursos, que no están sujetos a un control centralizado, usando interfaces y protocolos estándares, abiertos y de propósito general para proveer de servicios relevantes”.
Ya en 1969, Leonard Kleinrock, uno de los padres de Internet, decía: “Probablemente veremos la propagación de los servicios de computación (“computer utilities”) que, como actualmente la luz o el teléfono, llegarán hasta casas y oficinas de todo el país”. Kleinrock ya asemejaba estos servicios computacionales a los servicios telefónicos o eléctricos, de ahí el término Grid, con el que se denomina en inglés la red eléctrica.
Entre un Grid eléctrico y uno computacional, no obstante, existen algunas diferencias. Mientras que la electricidad es producida más económicamente centralizada en una gran central, se caracteriza por una métrica muy simple y se accede a través de una interfaz de conexión estandarizada, los recursos computacionales son producidos más económicamente de forma distribuida con servidores o clusters, se caracterizan por una métrica altamente compleja y se acceden mediante interfaces de software en proceso de estandarización.
Tras el desarrollo inicial de Internet durante los últimos treinta años y la revolución que ha supuesto el World Wide Web, se desarrolla el concepto de Grid de cálculo con el fin de compartir y utilizar recursos de computación. Este concepto se amplía con la utilización de recursos de almacenamiento masivo distribuido, dando lugar a Grid de datos.
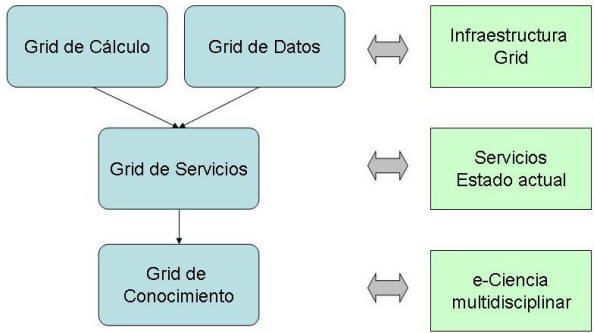 |
Fig. 2. Evolución Grid |
Estos primeros pasos en el concepto de Grid están evolucionando para constituir el llamado Grid de servicios, que depende de cada área temática con servicios específicos. Estamos actualmente en esta fase. La meta prevista en esta evolución es el llamado Grid de conocimiento para compartir no sólo cálculo, datos o servicios sino también experiencia y conocimiento científico y técnico (figura 2). Este concepto justifica el nombre de e-Ciencia.
Algunas aplicaciones clásicas de la e-Ciencia son: Astronomía y Espacio, Biomedicina y Ciencias de la Salud, Ciencia y Tecnología de Materiales, Ciencias de la Tierra, Física, Ingeniería, Química, Tecnologías para la Sociedad de la Información [75,76,77].
4. Arquitectura Grid
En un entorno Grid formado por diversos centros computaciones con diversas tecnologías e infraestructuras involucradas, resulta muy útil disponer de sistemas para proporcionar un único punto de acceso a los recursos de forma sencilla y transparente.
4.1. Middleware
Los sistemas Grid están formados por un conjunto de recursos heterogéneos que proporcionan distintas funcionalidades, como por ejemplo capacidades de computación, o almacenamiento de datos. El acceso a estos recursos se realiza a través de un middleware, que es el componente del Grid que facilita la infraestructura necesaria para poder interactuar con dichos recursos. Actualmente hay disponibles diversas iniciativas de middleware: Globus [10], Unicore [14], Condor [12], etc.
En otra definición se indica que el middleware es el software que conecta aplicaciones (mayormente distribuidas) con los recursos de software y hardware a nivel de plataforma. Como ejemplo puede darse el servidor de aplicaciones J2EE. En el contexto de Grid: Globus, Condor, MyGrid [69], Ibis, Proactive, JGRIM, Java Symphony.
4.2. Broker
Normalmente para realizar la gestión de los recursos se acostumbra a utilizar brokers ya que es una tarea que puede resultar demasiado compleja para los usuarios finales. Estos componentes reciben peticiones de los usuarios o aplicaciones que quieren acceder a recursos que tienen bajo su dominio, y en caso de ser necesario, interactúan con el middleware para llevar a cabo las acciones solicitadas. Actualmente hay disponibles diversas iniciativas de brokers (por ejemplo: eNANOS [13], GridWay [11], Nimrod-G [9], etc.). La manera de interactuar con cada uno de los brokers suele ser distinta, esto implica que si un usuario o aplicación quiere acceder a centros que están gestionados por distintos tipos de brokers, se tiene que conocer los distintos mecanismos de acceso y sus correspondientes APIs.
4.3. Arquitectura
Un Portal GRID se puede ver como una interface WEB a un sistema distribuido. La arquitectura básica de un portal responde a un esquema de arquitectura de tres capas: (1) la capa cliente, que se ejecuta mediante un navegador WEB; (2) la capa servidor que cumple la función de representar la lógica del negocio y (3) la capa de recursos y servicios GRID (repositorio de objetos, servidores computacionales, base de datos, etc.). Los clientes y el servidor típicamente se comunican vía HTTP permitiendo que cualquier navegador WEB sea usado. La capa servidor simplemente accede a ficheros locales para servir páginas pero también puede dinámicamente generar páginas web mediante la ejecución de scripts CGI y/o mediante interacción directa o indirecta con los recursos back-end. La interacción con la tercera capa puede lograrse en algún protocolo o de manera apropiada. Usando esta arquitectura general, los portales pueden ser construidos para que soporten aplicaciones de una amplia variedad (ciencia, educación, compras, etc.). Para hacerlo efectivamente, sin embargo, se requiere un conjunto de herramientas de construcción de portales que puedan ser personalizados para cada área de aplicación.
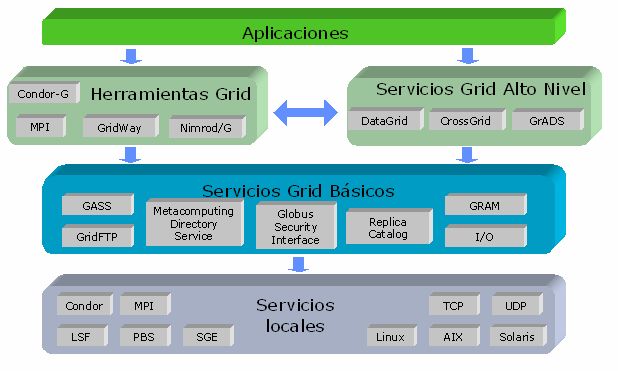 |
Fig. 3. Arquitectura Grid |
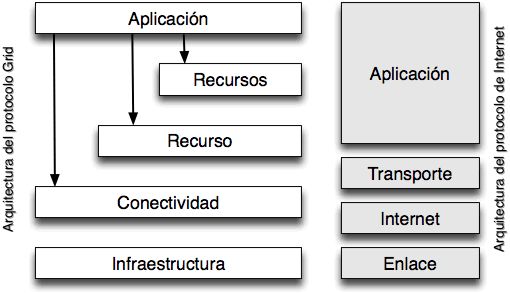 |
Fig. 4. Arquitectura Grid |
4.4. OGSA
Las tecnologías están evolucionando hacia Open Grid Services Architecture (OGSA) [15], en el cual una grid provee un conjunto extensible de servicios que organizaciones virtuales pueden sumar de varias formas. OGSA propone semánticas uniformes para exponer los servicios (llamada servicios grid), basada en conceptos y tecnologías a partir de ambas comunidades de servicios web y grid. OGSA define mecanismos estándares para crear, nombrar y descubrir instancias de servicios grid, así provee transparencia de localización y múltiples protocolos enlazan las instancias de los servicios y se soporta la integración con facilidades de la plataforma subyacente nativa.
Los esfuerzos de OGSA apuntan a definir un modelo de recursos comunes que es una representación abstracta de ambos recursos reales como los nodos, procesadores, discos, sistema de ficheros y recursos lógicos. Se provee operaciones comunes y se soporta los múltiples modelos de recursos subyacentes. Las abstracciones y servicios OGSA proveen construcciones en bloques que los desarrolladores pueden usar para implementar una variedad de servicios GRID de alto nivel, pero los servicios OGSA son en principio lenguajes de programación y modelo de programación neutrales. OGSA pretende definir la semántica de una instancia de un servicio grid: cómo es creado, cómo es nombrado, cómo se determina su tiempo de vida, cómo se comunica con el, etc.
Sin embargo, OGSA no se dirige a cuestiones del modelo de implementación de programación, lenguaje de programación, herramientas de programación o entornos de ejecución. La definición e implementación de OGSA producirá un efecto significativo sobre los modelos de programación grid debido a que este puede ser usado para soportar e implementar los servicios OGSA y los modelos de alto nivel pueden incorporar el modelo de servicios OGSA ofreciendo mecanismos de programación de alo nivel para usar esos servicios en aplicaciones grid. Por ejemplo el proyecto Globus en el año 2002 se comprometió a desarrollar una implementación open source mediante la evolución del Toolkit Globus hacia un toolkit conforme OGSA.
4.5. Herramientas disponibles
Para poder construir y utilizar un Grid es necesario conocer y utilizar una serie de herramientas en forma de bibliotecas de funciones, aplicaciones, etc. éstas se pueden dividir en tres grupos: toolkits, planificadores y entornos de desarrollo.
4.5.1. Toolkits (middleware)
Un toolkit es un conjunto de aplicaciones y bibliotecas de funciones que implementa la infraestructura básica de un Grid. Un toolkit proporciona servicios de seguridad, autenticación, información, comunicación entre recursos, ejecución de aplicaciones, transferencia de datos, etc. a los usuarios y programadores del Grid. Existen varios toolkits, de los que se destacan Legion, UNICORE y Globus.
4.5.1.1. Legion
Legion [16] es un toolkit basado en objetos, desarrollado en la Universidad de Virginia. Proporciona las infraestructuras necesarias para que un conjunto heterogéneo de maquinas distribuidas geográficamente funcionen de forma coordinada, presentando al usuario una sola máquina virtual.
Este enfoque totalmente orientado a objetos dificulta la interacción con aplicaciones legacy; tanto mas cuando se promueve la creación de aplicaciones paralelas con lenguajes nuevos o adaptados, como Mentat o Basic FORTRAN Support (un conjunto de directivas para FORTRAN).
4.5.1.2. UNICORE
UNICORE [14,66,67] (UNiform Interface to COmputer REsources) proporciona a los usuarios de los centros de supercomputación alemanes un interfaz gráfico para la preparación de trabajos y acceso seguro e intuitivo a los recursos de computación. Oculta las particularidades de cada sistema para facilitar el desarrollo de aplicaciones distribuidas.
UNICORE está diseñado para trabajo por lotes. Un trabajo en UNICORE consiste en un conjunto de tareas, con dependencias que indican relaciones temporales o transferencias de datos. La petición de ejecución de un trabajo indica dónde se deben ejecutar las tareas que la forman, y qué recursos requieren. Las tareas también se pueden dividir en subtareas, creando de este modo una jerarquía por la que diferentes partes de un trabajo se pueden ejecutar en distintos sistemas.
Los objetivos de diseño de UNICORE incluyen: un interfaz de usuario uniforme y fácil de usar, una arquitectura abierta basada en el concepto de tareas abstractas, una arquitectura de seguridad consistente, y mínima interferencia con los procedimientos administrativos locales.
4.5.1.3. Globus
Globus [10] es el toolkit estándar de facto para la construcción de Grids. Es un proyecto desarrollado por varias universidades, empresas y administraciones públicas de los Estados Unidos. Consiste en una serie de componentes que proporcionan servicios básicos, como seguridad, información y gestión de los recursos, y comunicaciones.
Globus se concibe como un conjunto de servicios, que se pueden utilizar de forma independiente, si fuera necesario:
- Globus Resource Allocation Manager (GRAM) – Es el componente que proporciona servicios de gestión de recursos y de creación, monitorización y gestión de procesos. GRAM convierte las peticiones, expresadas en un lenguaje llamado RSL (Resource Specification Language), en órdenes para los planificadores y computadores locales.
- Grid Security Infrastructure (GSI) – Es un servicio de autenticación y cifrado, que permite a la vez la gestión local de los permisos de acceso de los usuarios y el single sign-on (acceder a todos los recursos del Grid teniendo que autenticarse sólo una vez).
- Monitoring and Discovery Service (MDS) – Es un servicio de información del Grid, que proporciona los datos utilizando un directorio LDAP. MDS proporciona un mecanismo uniforme para acceder a información sobre la configuración de los servidores, la red, los recursos disponibles y ocupados, etc.
- Global Access to Secondary Storage (GASS) – Este componente implementa un conjunto de estrategias de movimiento de datos, que permiten que los programas que se ejecutan en lugares remotos puedan acceder a datos locales.
- Nexus y Globus-IO – Proporcionan servicios de comunicaciones para entornos heterogéneos.
- Heartbeat Monitor (HBM) – Es un componente que permite a los administradores del sistema y/o los usuarios detectar los fallos de componentes del sistema o procesos en ejecución.
Existe un API (Application Programming Interface) publicado para cada componente, lo que permite realizar aplicaciones que utilicen estos servicios. También se proporcionan herramientas de línea de comandos para uso por parte de los usuarios.
4.5.2. Planificadores
Un planificador es un sistema que es capaz de asignar recursos a las tareas que los usuarios desean ejecutar. Los planificadores “clásicos” funcionan en un cluster de ordenadores o en una red local; de muchos de ellos existen versiones Grid, capaces de planificar recursos situados incluso en distintos continentes. Es el caso de Condor-G y Nimrod-G.
4.5.2.1. Condor-G
Condor [17,62], originalmente, era un sistema diseñado para utilizar ciclos de CPU de estaciones de trabajo ociosas, para aprovechar potencia de cálculo que, de otro modo, no se utilizaría. Sin embargo, hoy en día es un planificador de tareas por lotes dotado con un mecanismo de colas de trabajos, políticas de planificación, monitorización y gestión de recursos. Cuando un usuario envía un trabajo a Condor, éste lo pone en una cola, y siguiendo una determinada política de planificación elige dónde y cuándo lo ejecuta; al ejecutarlo sigue su progreso y luego informa al usuario cuando termina.
Condor-G es la versión Grid de Condor, que utiliza Globus para la gestión de recursos, envío de trabajos y monitorización, lo cual le permite conocer y utilizar recursos distantes.
4.5.2.2. Nimrod-G
Nimrod [18,63,64] es una herramienta que facilita la realización de experimentos basados en la ejecución del mismo proceso con distintos parámetros de entrada: por ejemplo, permitiría probar un modelo meteorológico varias veces con datos de entrada ligeramente distintos cada vez. El usuario sólo tiene que crear un fichero de plan que contiene descripciones de los parámetros disponibles, sus posibles valores, la forma de ejecutar el experimento, etc.; Nimrod se encarga de buscar y reservar los recursos necesarios, de acuerdo con cierto objetivo especificado por el usuario: minimizar el tiempo de ejecución, minimizar el coste de los experimentos, etc.
La versión Grid de Nimrod, Nimrod-G [9], utiliza Globus para iniciar los trabajos en maquinas distantes.
4.5.3. Entornos de desarrollo
Un entorno de desarrollo consiste en un conjunto de aplicaciones y bibliotecas de funciones destinadas a desarrollar aplicaciones para el Grid. Normalmente, cada entorno de desarrollo se asocia a un toolkit. En este grupo de herramientas se incluyen las bibliotecas de programación paralela, como MPICH-G2.
4.5.3.1. GridGain
GridGain [78] es un API para computación grid codificada en y para Java. GridGain es un producto open source bajo licencia LGPL-2.1 con una menor parte bajo licencia Apache 2.0, que se dió a conocer en julio del 2007. Como muchas otras APIs y Librerías GridGain facilita la paralelización de procesos, de manera que se puedan compartir recursos, reducir los tiempos y mejorar la performance. Las claves de GridGain se pueden resumir en dos puntos: Map/Reduce y SPI (Service Provide Interface).
El paradigma de programación detrás de GridGain es Map/Reduce [79], un enfoque de resolución de problemas del estilo “divide y vencerás” [80,81], el cual se ha hecho popular por su aplicación por Google. La idea subyacente es simple: dividir un problema en partes más pequeñas y ejecutarlas en paralelo en los nodos de una red (parte map). Cuando los nodos han finalizado, se componen los resultados individuales para obtener el resultado final (parte reduce). Si un problema puede ser expresado en términos de operaciones map y reduce se puede escalar a través de varios nodos y resolver problemas grandes. En el modelo de Map/Reduce, el mapping es un proceso que divide la tarea inicial en subtareas y las asigna a los nodos de la grid. Generalmente el mapping involucra la propia lógica de la división, e incluye el balance de carga (asignación de las subtareas a los nodos), manejo de potenciales fallas (fail over) y resolución de colisiones.
En GridGain, el enfoque Map/Reduce es mejorado por un mecanismo denominado “balance de carga temprano/tardío”. Cuando una tarea comienza su ejecución, primero se realiza el mapping inicial, que la divide en un número de subtareas y las asigna a uno o más nodos grid. Esto se denomina balance de carga temprano. Luego las subtareas viajan a los respectivos nodos remotos para ser ejecutadas. Cuando una subtarea arriba a un nodo grid destino está sujeta a colisiones. Un proceso denominado SPI es llamado cada vez que una subtarea arriba a un nodo. De acuerdo al estado de la cola (schedulling) SPI puede: cancelar la subtarea, dejar la subtarea esperando en la cola, transferir la subtarea a otro nodo para su ejecución, o comenzar la ejecución localmente. Este mecanismo se denomina balance de carga tardío. Este ocurre en la ejecución del proceso y en el nodo destino. La característica importante es que puede existir una diferencia de tiempo importante entre los dos balances de carga. El tipo de balance de carga de GridGain ayuda a adaptar la ejecución de la tarea a la naturaleza no-determinística de ejecución en la grid eficazmente.
SPI es un mecanismo muy poderoso que configura y afecta dinámicamente casi todos los aspectos del framework de computación grid: comunicación, descubrimiento, fallas, resolución de conflictos, balance de carga, manejo de la topología, etc.
4.5.3.2. MPICH-G2
MPI [68] (Message Passing Interface) es un API estándar para la realización de aplicaciones paralelas de paso de mensajes. Existe una gran cantidad de implementaciones de este estándar, que utilizan muchos tipos de redes de comunicación, y en muchas arquitecturas distintas.
MPICH es la implementación mas extendida del MPI estándar. Su portabilidad se fundamenta en un diseño en dos capas. La capa inferior, conocida como ADI (Abstract Device Interface), oculta la mayoría de los detalles dependientes del hardware. El diseño del ADI permite realizar implementaciones eficientes sobre diferentes arquitecturas, mientras que la capa superior se encarga de la semántica y la sintaxis de la mayor parte de la biblioteca MPI. Cada implementación distinta de la capa ADI se denomina “dispositivo”, y cada dispositivo define una implementación diferente.
MPICH-G2 [19,65] es la segunda generación de la biblioteca MPICH-G. Esta biblioteca extiende la implementación de MPICH para poder utilizar los servicios proporcionados por Globus. Está implementada como uno de los “dispositivos” de MPICH: el dispositivo llamado “globus2”. MPICH-G2 es capaz de acoplar múltiples maquinas de diferentes arquitecturas para ejecutar aplicaciones MPI utilizando servicios Globus.
5. Portales Grid
Para permitir el uso de la grid por parte de los usuarios finales existen dos opciones: la primera de ellas es que la use directamente desde un cliente de escritorio y la otra que se use un portal grid basado en la web.
La primera es un acercamiento tradicional del software distribuido. De acuerdo con “grid middleware” (El grid middleware está compuesto por servicios grid, que a su vez están basados en la tecnología de servicios web), se pueden desarrollar herramientas para el cliente que proporcionan funcionalidades para ejecutar tareas relacionadas con la grid. Estas herramientas requieren normalmente que los puertos estén abiertos para realizar tareas como la transferencia de archivos usando GridFTP. Este acercamiento trabaja con instituciones particulares como un campus por ejemplo, pero requiere de mucho trabajo administrativo y no es tan flexible como el segundo acercamiento. La Web es una plataforma ideal para los servicios distribuidos, y casi todos los equipos de escritorio tienen un browser (al igual que dispositivos como teléfonos móviles y PDAs).
Esto hace que un portal grid basado en la web sea una opción simple para proporcionar los mismos servicios que un cliente de escritorio. Y lo mejor de todo es que los portales grid no requieren de la instalación de software en el cliente, solamente un browser.
Para facilitar la adopción y utilización de Grids por parte de las distintas comunidades de usuarios, es necesario presentar el Grid de una forma visual, atractiva e intuitiva. Una solución común a esta necesidad consiste en la elaboración de portales web, a los que se puede acceder desde cualquier ordenador dotado de un navegador, para operar con el Grid. Este enfoque evita que los usuarios tengan que instalar y administrar aplicaciones en sus estaciones de trabajo, y permite que puedan acceder al Grid desde cualquier lugar.
Los portales Grid se dividen, generalmente, en portales orientados al usuario y portales orientados a una aplicación [20]. Los primeros son portales genéricos, diseñados para que los usuarios puedan utilizar los recursos del Grid. Los portales del segundo tipo son portales diseñados para que los usuarios utilicen una determinada aplicación; por ejemplo, portales para enviar datos a una aplicación de cálculo de interacciones electrostáticas entre moléculas (APBS [21]) y recoger los resultados.
Los portales se elaboran utilizando lenguajes de programación y herramientas estándar, basándose en kits de desarrollo: bibliotecas de funciones, aplicaciones y conjuntos de plantillas que facilitan la elaboración de portales de usuario y/o portales de aplicación. Estos kits de desarrollo se elaboran en base a “Commodity Grid kits” (CoG kits). Estos CoG kits son conjuntos de componentes que permiten acceder a los servicios del Grid desde lenguajes de programación estándar (Commodity) [22].
Los portales Grid basados en la Web, o Portales Grid [23], han establecido herramientas efectivas para proveer a los usuarios de las redes Grid con interfaces simples e intuitivas para acceder a la información de la Grid y utilizar sus recursos [24]. Se están realizando portales para Grids de gran tamaño, fundamentalmente en Europa y Estados Unidos. El middleware Grid –por ejemplo Globus- provee poderosas herramientas para integrar una gran cantidad de computación y recursos de almacenamiento, instrumentos, sensores, etc. Pero generalmente estos middlewares poseen una interfaz de usuario y APIs muy complejas para el usuario final. Los portales Grid hacen que estos ambientes Grid de cómputo y almacenamiento distribuido y heterogéneo sea más accesible para los usuarios y científicos utilizando una interfaz de usuario estándar y conocida, tal como la Web. Los portales Grid, y otros portales basados en Web, permiten a los desarrolladores y usuarios la capacidad de personalizar el contenido y la presentación para el conjunto de herramientas y servicios ofrecidos. Un portal Grid puede habilitar la ejecución automática de aplicaciones específicas, brindar links específicos para una colección de datos científicos de una determinada disciplina, integrar y ocultar el flujo de datos entre aplicaciones, automatizar la creación de colecciones de archivos de resultados de aplicaciones, etc. El portal también puede proveer una “vista” del estado interno del Grid, informando por ejemplo el entorno de ejecución, la disponibilidad de los recursos, el estado de ejecución de los trabajos y la carga del sistema en un momento determinado.
El software usado para construir los portales Grid debe interactuar con el middleware que se ejecuta en los distintos recursos del Grid, y en algunos casos debe proveer la funcionalidad adecuada cuando el middleware Grid no está disponible para un recurso específico. El software del portal debe ser compatible con el software de los servidores Web y sus clientes (browsers). Con el tiempo han surgido varias herramientas de desarrollo general para portales Grid, simplificando la tarea de los desarrolladores para utilizar las complejas tecnologías y servicios Grid, generalmente a través de una sencilla interface Web. Con el advenimiento de los servicios Web, protocolos de interoperabilidad y estándares se están desarrollando para los servicios Grid. A medida que mejore la definición de estos estándares y servicios, el desarrollo, implementación, mantenimiento y uso de los portales Grid será también más fácil.
El software para la creación de portales Grid debe integrar un gran variedad de otros sistemas hardware y software. Por lo tanto los portales representan un escenario de integración de tecnologías. Esto es parte del rol que los portales Grid deben realizar en el layer middleware de Grid: los portales administran la integración de los paquetes middleware de bajo nivel y refuerzan la integración con otras herramientas. Por otro lado, proyectos tales como GridPort [25], Grid Portal Development Toolkit [26], y el proyecto Common Component Architecture [27] han demostrado que las herramientas integradas permiten desarrollos generales de aplicaciones Grid tanto como los portales Grid basados en Web.
5.1. Diferencia entre portal grid y portal consumo
La cualidad dominante de los servicios grid es que sea stateful (tienen estado y guardan en memoria información), mientras que un servicio web tradicional es stateless (no tienen estado y no guardan en memoria información).
Web Services Resource Framework (WSRF) estandariza cómo hacer servicios web stateful. De hecho actualmente los servicios web y las comunidades de la grid se están combinando [28].
5.2. Portales grid de primera y segunda generación
La primera generación de portales grid fueron construidos con la ayuda de Perl GridPort toolkit v2 [25] o tecnología Java Grid Portal Development Kit (GPDK) [29].
GridPort y GPDK usan funcionalidades Grid para programación de APIs y provisión de herramientas. En la práctica estas herramientas fueron desarrolladas de acuerdo a los requerimientos de cada proyecto sin considerar la reutilización de código. La adopción de tecnologías de portales demostró que podían ser desarrollados servicios web de uso común.
Mientras el desarrollo de Portales Grid se comienza a reutilizar, existen proyectos como Jetspeed1 [33] y Apache como proveedores de portlets. Por ejemplo la primera versión de U.K NGS [30] y la primera versión de Open Grid Computing Environment (OGCE) [31] están basados en Comprehensive Collaborative Framework (CHEF) [32]. El CHEF es el antecesor de Sakai [60], el cual fue construido en Jetspeed1 para proveer estándares que no soporten portlets.
Jetspeed1 muestra una aproximación para construir componentes web reutilizables, por ejemplo “Java Portlets” los cuales pueden ser compartidos por los desarrolladores. WSRP V1.0 y Java Portlets especificación JSR 168 son reconocidas por OASIS [34] en el 2003 para formar la base de lo que hoy en día es la segunda generación de Portales Grid.
La segunda generación de portales grid se basa en estándares. En particular, JSR 168 ha sido adoptado por desarrolladores de portales grid. JSR 168 y WSRP v1.0 apuntan a resolver problemas de interoperabilidad entre portales y desarrollo de los portales. Además la segunda generación de portales grid está actuando como clientes de servicio de manera que caben dentro de la Arquitectura Orientada a Servicio (SOA).
Los siguientes Portales Grid: OGCE Release 2, GridPort V4, NGS Portal release 2, constituyen los más importantes y grandes proyectos actualmente en desarrollo.
6. Herramientas para el desarrollo de Portales Grid
Java es, actualmente, la tecnología mas utilizada para la elaboración de aplicaciones web; existe una gran cantidad de aplicaciones, bibliotecas de funciones y documentos acerca del tema, lo que hace más aconsejable el uso de un kit basado en Java.
Los kits y herramientas más importantes o populares actualmente para el desarrollo de portales grid son los siguientes:
6.1. GridPort
GridPort [25] es un kit de desarrollo de portales Grid de usuario y de aplicación. Estos portales se implementan mediante scripts escritos en el lenguaje de programación Perl (con la ayuda de un CoG kit implementado en este lenguaje, “Perl CoG” [36]), que son invocados a través del servidor web utilizando el interfaz estándar CGI (Common Gateway Interface).
GridPort se creó para el portal NPACI HotPage [37, 38], un portal de usuario que permite acceder a recursos, tanto de supercomputación y almacenamiento masivo, situados en cuatro universidades de los Estados Unidos.
GridPort incluye un conjunto de interfaces de portlets y servicios que proveen acceso a un amplio rango de backend (grid) y servicios de información.
6.2. GPDK
GPDK [39, 41] (iniciales de Grid Portal Development Kit) proporciona tanto un entorno de desarrollo para crear nuevos portales como una colección de componentes Java para realizar operaciones básicas sobre el Grid, tales como envío de tareas, transferencias de ficheros, obtención de información, etc.
GPDK propone una arquitectura de tres capas: servidor web, Globus y Grid. Primero, el navegador se comunica con el servidor web utilizando una conexión segura. El servidor web puede acceder a los servicios del Grid utilizando la infraestructura de Globus.
Un portal de GPDK es una aplicación web construida utilizando tecnologías JSP (Java Servlet Pages) y Java Beans, que se ejecutan sobre Tomcat, el servidor de aplicaciones Java de referencia. Tomcat se puede configurar para funcionar tras cualquier servidor web del mercado.
Los componentes Java proporcionados por GPDK proporcionan un interfaz de alto nivel que engloba las funcionalidades de “Java CoG kit” [40] y de otras bibliotecas de clases commodity que proporcionan servicios de gestión de certificados y consulta de información. “Java CoG kit” proporciona acceso a servicios del Grid a través del entorno Java. Con “Java CoG kit” se proporcionan bibliotecas de clases para incorporar en aplicaciones Java, así como utilidades de línea de comandos implementadas con estas clases.
GPDK fue un producto exitoso para la creación de portales específicos de algunos grupos de investigación como el portal computacional de química GridGaussian, el portal MIMD Lattice Computation (MILC), etc. Sin embargo, en el diseño de GPDK las capas de presentación y de lógica están acopladas, además de no ser conformes a ninguna especificación de portal/portlets. Esto hace que el portal resulte menos extensible y escalable. Actualmente GPDK no tiene mas soporte y la mayoría de sus autores se han sumado al proyecto GridSphere.
6.3. Grid Resource Broker
Grid Resource Broker (GRB) es un portal web que permite a los usuarios manejar Grids mediante un interfaz de usuario fácil de usar, de forma segura e independiente de su localización. Permite que los usuarios no tengan que aprender los comandos de Globus ni modificar sus programas ya existentes.
Al igual que GPDK, GRB tiene una arquitectura de tres capas: un navegador se conecta de forma segura a un servidor web que reside en la primera capa; éste utiliza Globus, que reside en la segunda capa, para proporcionar acceso a los recursos computacionales de la tercera capa (Grid).
El portal GRB fue construido como ejemplo de utilización de la biblioteca GRB [43], ésta es una biblioteca de funciones en C para acceder de una forma sencilla a algunos de los servicios de Globus: envío de trabajos, gestión de trabajos enviados, consultas a los servicios de información y transferencias de ficheros.
6.4. GridSphere
GridSphere [44] es un proyecto de creación de un entorno de desarrollo de portales basado en “portlets”. Un “portlet” es un componente que se puede integrar en un portal web; funcionan como pequeñas aplicaciones web gestionadas desde un programa “contenedor de portlets”. Se espera que esta arquitectura basada en portlets permita utilizar distintas tecnologías según las necesidades del desarrollador del portal.
GridSphere se encuentra en estadios tempranos de desarrollo. Uno de los elementos claves de GridSphere es que soporta configuración dinámica de contenidos basado en los requerimientos de los administradores y usuarios individuales [45]. Otra característica importante es que GridSphere provee portlets específicos de grid y APIs para desarrollar las capacidades gris (Grid Resource Information Service) del portal. La principal desventaja es que no soporta WSRP.
6.5. LifeRay Portal
El portal Liferay [46] es más que un contenedor de portales [47]. Proporciona otras características útiles como: Content Management System (CMS), WSRP, Single Sign On (SSO). Es open source, 100 % conforme a JSR portlet API y WSRP. Liferay es apropiado para el desarrollo de portales enterprise. Algunas instituciones y companías que adoptaron Liferay para crear sus portales son: EducaMadrid, Goodwill, Jason’s Del, Oakwood, Walden Media, etc.
6.6. eXo platform
La plataforma eXo [48] puede ser vista como un portal y un CMS [17]. La plataforma eXo 1 es más bien un framework para portales. La plataforma eXo 2 propone una estrategia de Línea de Producto [49] ya que ha sido realizada pensando en que los usuarios finales necesitan utilizar soluciones empaquetadas en lugar de productos monolíticos. Actualmente es el componente principal en el cual puede ser construída una línea de productos. Adopta las especificaciones Java Server Faces y Java Content Repository (JCR – JSR 170), así como JSR-168 y soporta WSRP.
6.7. Stringbeans
Stringbeans [50] es una plataforma para la construcción de portales de información enterprise. La plataforma está compuesta de 3 componentes: (i) un contenedor de portales/servidores, (ii) una plataforma Web, y (iii) una máquina de automatización de procesos. Adhiere a JSR-168 y soporta WSRP. Stringbeans fue usada por UK National Grid Service (NGS) [51].
6.8. uPortal
uPortal [52] es un framework para producir portales de campus. Es desarrollado por JA-SIG (Java Special Interest Group). Adhiere a JSR- 168 y soporta WSRP. uPortal es ampliamente usado en la creación de portales universitarios, por ejemplo la universidad de Bristol.
6.9. Pluto
Pluto es un subproyecto del proyecto Apache Portal. Es la implementación de referencia de JSR 168 [53]. Pluto simplemente provee un contenedor de portlets para que el desarrollador del portal testee los portlets y no provee ningún portlets específico.
6.10. Jetspeed
Jetspeed es otro proyecto Apache Portal, que incluye Jetspeed-1 [33] y Jetspeed-2 [54]. Jetspeed-1 provee implementación open source de Portal de información Enterprise usando Java y XML. Jetspeed-2 es la próxima generación del portal Enterprise, y ofrece varias mejoras en la arquitectura respecto de Jetspeed-1. Jetspeed es más sofisticado que Pluto.
6.11. IBM WebSphere Portal
El portal WebSphere Portal [55] de IBM es un framework que incluye un servidor, servicios, herramientas y otras características que se integran en un portal único personalizable. Implementa JSR 168 Portlet API y WSRP. El WebSphere Portal es una herramienta poderosa y ampliamente usada por varias compañías de negocios y enterprise.
6.12. P-GRADE
P-GRADE [56,59] es un portal orientado al workflow grid, con el principal objetivo de permitir a los usuarios manejar el ciclo de vida (workflow) completo de las complejas aplicaciones grid. P-GRADE soporta el desarrollo gráfico de los workflows creados a partir de tipos diferentes de componentes (secuencial, MPI o PM), ejecución de trabajos-workflows en la grid según las credenciales de los usuarios, y análisis de la traza de los datos monitoreados mediante la construcción de visualizaciones.
El servidor de aplicaciones del portal está construido sobre GridSphere, que provee tecnología basada en portlets. Como resultado, varias funcionalidades del portal pueden ser implementadas en portlets independientes, situándose P-GRADE como un portlet. P-GRADE ha sido integrado con Globus-2 (SuperGrid, LCG-2 y GridLab test-bed [61]).
6.13. JSR 168 y WSRP V1.0
Los dos estándares JSR-168 [57] y WSRP [58] (Web Services for Remote Portlets) garantizan que los portlets sean pluggables e independientes del framework.
JSR 168 es una especificación para los desarrolladores de portales Java. Un portal es una aplicación basada en la web que provee contenido de diversas fuentes y recibe la capa de presentación de sistemas de información. Un portlet es un componente Web basado en Java, manejado por un contenedor de portlet que procesa peticiones y genera el contenido dinámico. Un contenedor del portlet contiene portlets y provee de ellos el ambiente en tiempo real requerido.
JSR 168 es una especificación para la estandarización de comunicaciones entre portlets y un contenedor de portlets definidos por un conjunto de APIs de Java. Además esta especificación hace posible que desarrolladores de portlets intercambien componentes web. Estos portlets pueden ser mostrados por el “JSR 168 compliant” contenedor de portlet, sin modificar el código fuente. Los Portales ahora se construyen con contenedores de portal, los cuales manejan el ciclo de vida del portlet.
Un típico framework de un portal generalmente proporciona funcionalidades como administración de cuentas de usuario y el despliegue de los portlets. Por lo tanto, la carga en los desarrolladores de portales se disminuye, y los desarrolladores pueden centrarse en el desarrollo del portlet, particularmente en la capa de la lógica del negocio.
Para reutilizar el contenido Web (portlets) publicado usando lenguajes diferentes a Java como por ejemplo PERL o PHP se propuso la especificación del OASIS WSRP V1.0. WSRP separa portlets de portales, este introduce los conceptos del productor y del consumidor. Un productor es un proveedor de servicio, y un consumidor es un cliente del servicio. Desafortunadamente, la actual puesta en práctica de WSRP para código abierto sigue siendo inmadura. El grupo de EDINA es uno de los pocos o único productor de código abierto WSRP escrito en otro lenguaje, usando Perl. JSR 286 y WSRP V2.0, sucesores de JSR 168 y WSRP V1.0, se programaron para ser lanzado en el 2007, pero ambas especificación han sido aprobadas recientemente (JSR 286 en junio de 2008 y WSRP V2.0 en abril de 2008) y deben proporcionar las mejoras que solucionarán problemas como la comunicación entre portlets y la administración del ciclo vital del portlet.
7. Caso de Estudio: SURAgrid
SURAgrid [71,72] (Southeastern Universities Research Association) es un consorcio de organizaciones que colaboran y combinan sus recursos para ayudar a producir, mediante la tecnología grid, una infraestructura a menor costo. La visión de SURAgrid es orquestar el acceso a un conjunto rico de capacidades distribuidas para satisfacer las necesidades de usuarios diversos. Las capacidades incluyen recursos localmente distribuidos, herramientas y ambientes específicas de proyecto, acceso HPC (High - Performance Computing), y entradas a la cyber-infraestructura nacional e internacional.
7.1. Características Técnicas
- Portal: gridsphere
- Miembros: 62 instituciones
- Area geográfica: más de 16 estados
- Nodos: 560
- Almacenamiento: 6.6 TB
- Software: Linux, Condor, Globus, Rocks [74], Beowulf [73], MyProxy [70], OS X, etc
- Hardware: Intel, AMD, Sparc, Power G5
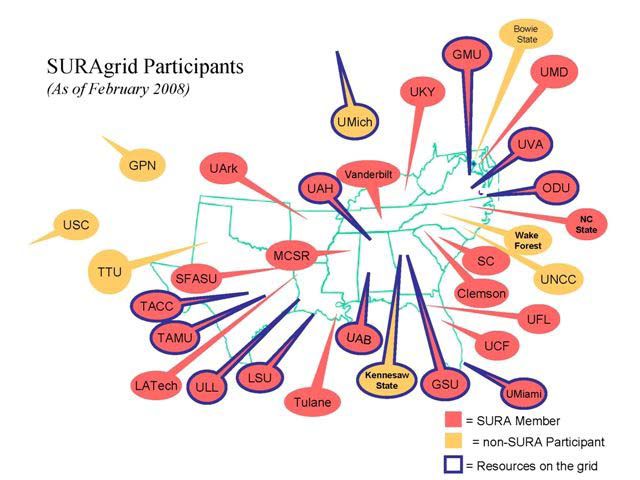 |
Fig. 5. Participantes de SURAgrid |
La posibilidad de disponer de una cyber-infraestructura regional refuerza la investigación proporcionando el acceso a los recursos más allá de los disponibles en los campus particulares.
7.2. SURAgrid soporta iniciativas de investigación regional:
- alentando y facilitando colaboraciones de investigación y desarrollo de propuestas colaborativas
- permitiendo el acceso a los recursos de HPC distribuídos capaces de apoyar una amplia variedad de modelos y aplicaciones de simulación
- proporcionando el acceso a los datos compartidos y herramientas de visualización
- simplificando el acceso y uso a los servicios de la cyber-infraestructura regionales y nacionales
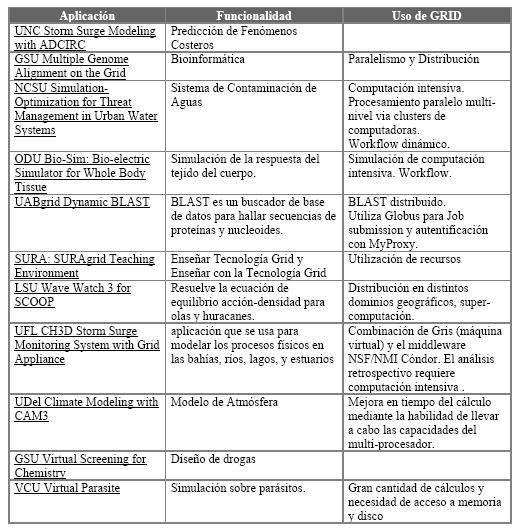
Por ejemplo las siguientes aplicaciones son desplegadas sobre SURAgrid.
.
|
La comunidad SURAgrid identifica y propone de manera activa nuevas aplicaciones para la ejecución en la caber-infraestructura. Actualmente se han identificados las siguientes aplicaciones para SURAgrid:
7.2.1. Hampton University Tokamak Divertor Map
En CFRT el área principal de investigación son los mapas matemáticos para calcular las trayectorias de las líneas de los campos magnéticos. Esta investigación se satisface ejecutándose en un número grande de procesadores en modo paralelo.
7.2.2. NCAT Protein Loop Structure Prediction
NCAT es un software que predice la estructura cíclica de las proteínas y en el entorno SURAgrid se desarrollará un benchmark que permitirá poner a punto la performance de la aplicación.
7.2.3. ODU Options Pricing
Este proyecto se enfoca en las implementaciones especializadas del árbol binomial. En particular, se aprovechará de la jerarquía de memoria, así como los sistemas de comunicación de los sistemas paralelos.
7.3. Vision de SURAgrid
El background de los participantes de SURAgrid es diverso al igual que sus expectativas. Algunos recién se han iniciado en los ambiente de computación grid y están trabajando para aumentar su propio conocimiento con las herramientas grid (como NMI Testbed y Globus Toolkit) y de esta forma aumentar las capacidades de las instituciones a las que pertenecen. Otros miembros representan Centros de Alta Performance de Computación con comunidades de usuario establecidas y recursos computacionales de producción que están buscando los beneficios de grid para extender el acceso a sus facilidades a una mayor audiencia. Otros miembros de SURAgrid son especialistas y expertos en investigación y desarrollo grid, que habiendo identificado las áreas críticas para la evolución de grid, encuentran en SURAgrid, la única grid posicionada para realizar test continuo de los objetivos comunes.
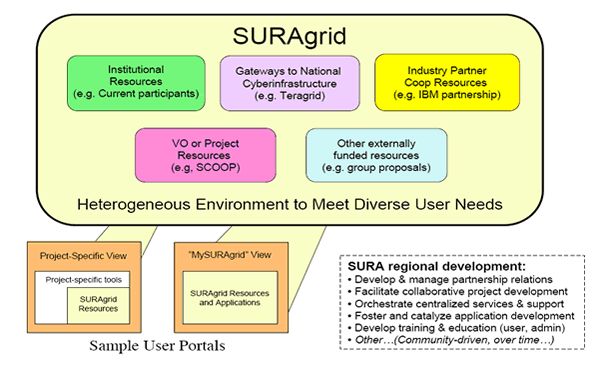 |
Fig. 6. Organización de SURAgrid |
Grid Information Browser
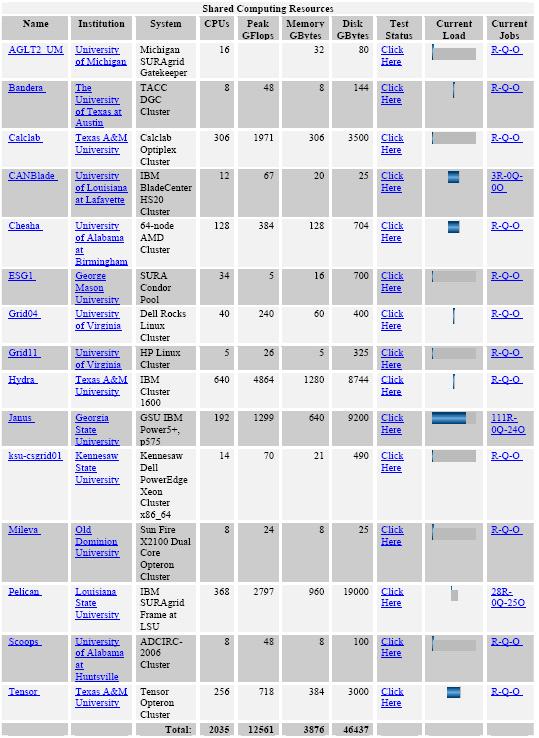 |
Fig. 7. Visor de Recursos en SURAgrid |
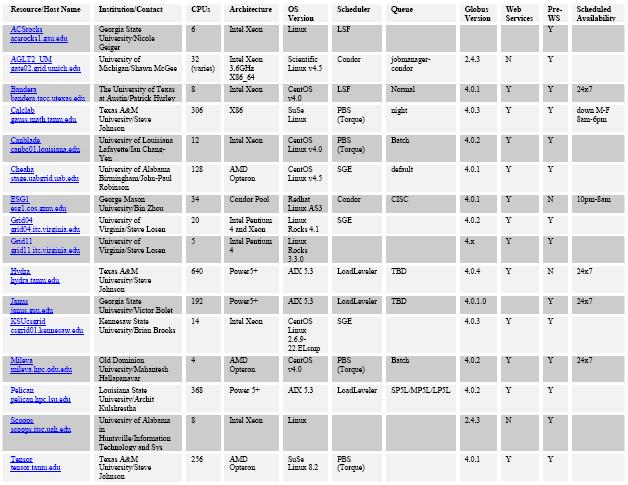 |
Fig. 8. Visor de Participantes en SURAgrid |
7.4. Compartiendo en SURAgrid
La intención de SURAgrid es replicar el ambiente colaborativo, multi-institucional y heterogéneo que es característico de la educación e investigación de más alto nivel. La implementación de tecnologías y políticas para la autenticación (authN) y autorización (authZ) entre las organizaciones autónomas es un tema de continua investigación en el desarrollo de la grid y un área clave de investigación para SURAgrid. En esto, SURAgrid está proporcionando a los participantes la oportunidad de explorar cómo pueden extenderse las soluciones de la autenticación locales para proporcionar el acceso a los recursos de la grid dentro de y más allá del campus, y ayudando a sostener el desarrollo de un ambiente grid de educación activo que pueda ser interconectado a una infraestructura global emergente.
7.5. SURAgrid
Para manejar la complejidad de los diversos ambientes y la duplicación de esfuerzo, AuthN/AuthZ son la clave de las actividades de SURAgrid. Una meta primaria de SURAgrid es crear una infraestructura escalable que provea la identidad institucional local (AuthN) mientras maneja acceso a los recursos compartidos (AuthZ) por los límites institucionales. Así se requieren menos perfiles de usuario y menos procesos para manejar, así como poder asegurar que esa identidad está verificada a través de una autoridad. Los participantes de SURAgrid están dirigiendo los objetivos AuthN y AuthZ en dos frentes principales:
- Implementando las herramientas para permitir a los campus elevar la identidad institucional local y las políticas de la autorización por SURAgrid y para manejar los servicios grid de manera similar a otras aplicaciones del campus;
- planeando y avanzando la infraestructura escalable dentro de un grid activo, desarrollando y explorando las herramientas para AuthN y AuthZ que faciliten seguridad en el deployment de aplicaciones grid.
Todos los miembros de SURAgrid tienen interés en como la grid y la computación de alta performance se intersectan y la necesidad de dirigir AuthN y AuthZ dentro de un multi-proyecto en un ambiente grid dinámico.
7.6. Autentificación
Autentificación (AuthN) es el acto de identificar a un usuario (no incluye la determinación de los recursos que puede acceder). AuthN es el proceso por el cual una entidad del mundo real es verificada para ser quien (persona) o que (nodo, instrumento remoto) se identifica (username, certificado, etc.). En este proceso, las credenciales de autentificación de las entidades del mundo real son evaluadas y verificadas. Ejemplos de credenciales son: tarjetas inteligentes, preguntas-respuestas, password, certificado de clave publica, ID de fotografía, impresión digital, etc. Los principios de SURAgrid respecto de AuthN especifican que:
- En la autenticación de usuario grid deben influir los procesos existentes de identificación locales de los campus. El AuthN a las aplicaciones debe ser transparente para los usuarios, mientras que se integre transparentemente con la infraestructura del campus existente y el ambiente de usuario.
- La autenticación local se traduce a la autenticación de grid. Los mecanismos de identidad locales en uso en los campus participantes de SURAgrid se incorporarán en un proceso basado en PKI requerido para la autenticación grid.
La autenticación local es un proceso IT fundamental que todos los campus de educación superior rutinariamente dirigen y que puede llevarse a cabo a través de varios mecanismos bien reconocidos. Se atiende la naturaleza heterogénea, ya que las instituciones que participan en SURAgrid necesariamente no llevan a cabo la autenticación local con el mismo mecanismo. Kerberos, LDAP, bases de datos de contraseñas, e incluso PKI son usados como mecanismos para establecer la identidad local. Los participantes de SURAgrid incorporan los componentes NMI para integrar sus procesos locales de autenticación con la autenticación grid, incluso MyProxy y KX.509.
En SURAgrid, se ha implementado el componente de seguridad Globus Center que usa internamente PKI.
MyProxy y KX.509 son los dos componentes usados como traductores entre el AuthN local y la infraestructura de un campus y PKI se emplea para transportar las identidades localmente autenticadas a la infraestructura de autenticación de grid. La herramienta GridMap de Globus se usa durante la traducción de la autenticación grid a local e informa a los recursos grid que el certificado de identidad grid ha sido verificado.
 |
Fig. 9. Ingreso al Portal Grid |
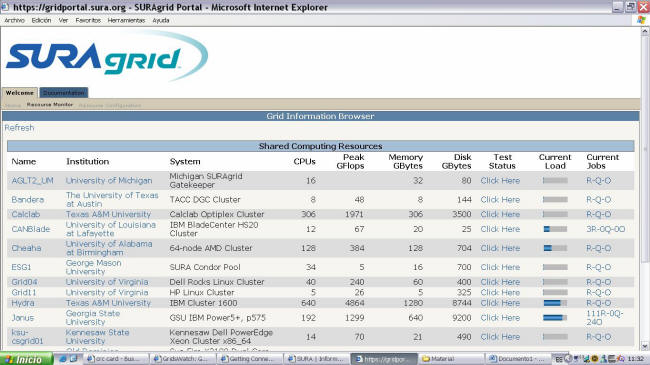 |
Fig.10. Monitoreo de Recursos Compartidos |
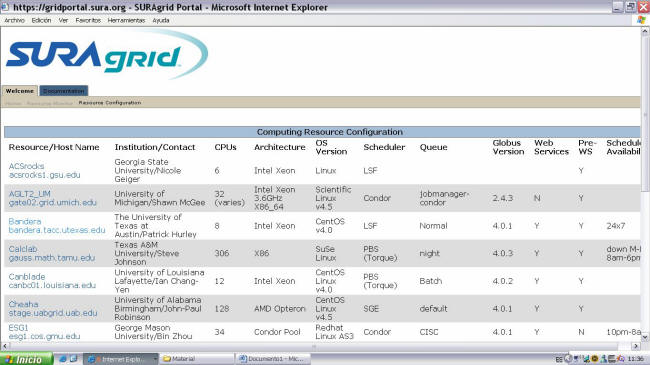 |
Fig. 11. Configuración de Recursos Computacionales |
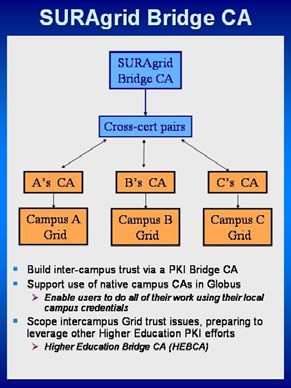
7.7. Escalar la GRID a través de un Bridge CA
Bridge CA fue seleccionado para la implementación en SURAgrid. Esta opción maneja el problema de escalar N2 en el que cada sitio sólo necesita intercambiar los certificados con el Bridge CA. El Bridge CA define una relación de confianza (o crédito) entre las instituciones cuando un usuario presenta su identidad grid (el certificado) a un recurso, (el recurso sabe si puede confiar en el sitio que emitió el certificado).
El desarrollo de AuthN/AuthZ, vió el potencial dentro de SURAgrid de demostrar el uso inmediato de Globus en un ambiente conectado como un precursor a la disponibilidad futura de HEBCA (Higher Education Bridge Certification Authority) como la autoridad de certificación subyacente.
Dado el uso de certificados para la autenticación de Globus Toolkit, un PKI Bridge parecía ser la solución más lógica para implementar la infraestructura de autenticación para una grid dinámica, multi-institucional. El Bridge podría proporcionar la infraestructura técnica para la certificación cruzada y para habilitar la autentificación entre sitios y también servir como catalizador de políticas y decisiones requeridas para soportar el uso de la grid en el mundo real.
|
Fig. 12. Inter-Institutional Sharing |
8. Referencias
[1] Ian Foster , “What is the Grid? A three point checklist”, Grid Today, 2002.
[2] Ian Foster and Carl Kesselman, editors. The Grid: Blueprint for a New Computing Infrastructure. Morgan Kaufmann, 1998.
[3] Smarr, L. and Catlett, C. Metacomputing. Comm. of the ACM, 35(6):44–52, 1992.
[4] DeFanti, T., Foster, I., Papka, M., Stevens, R., Kuhfuss, T. Overview of the I-WAY: Wide Area Visual Supercomputing. Int. J. Supercomp. App., 10(2):123–130, 1996.
[5] Viktors Berstis, Fundamentals of Grid Computing, Redbooks Paper, IBM, 2002.
[6] Miguel L. Bote-Lorenzo, Yannis A. Dimitriadis, and Eduardo Gómez-Sánchez, Grid Characteristics and Uses: a Grid Definition. European Across Grids Conference 2003: 291-298
[7] Viktors Berstis, Fundamentals of Grid Computing, Redbooks Paper, IBM, 2002.
[8] Libro blanco, e-CIENCIA en España, 2004. FUNDACIÓN ESPAÑOLA PARA LA CIENCIA Y LA TECNOLOGÍA. Edita: FECYT (Fundación Española para la Ciencia y la Tecnología), 2004. Madrid, España.
[9] D. Abramson, R. Buyya, J. Giddy. A Computational Economy for Grid Computing and its Implementation in the Nimrod-G Resource Broker. Future Generation Computer Systems. 18(8), 2002
[10] Globus Project Web Site. http://www.globus.org
[11] GridWay Web Site. http://asds.dacya.ucm.es/GridWay/
[12] M. Litzkow, M.Livny, M. Mutka. Condor – A Hunter of Idle Workstations. Proc. 8th International Conference of Distributed Computing Systems (ICDCS 1988). IEEE CS Press. San Jose, CA, USA. January 1998.
[13] I. Rodero, J. Corbalán, R.M. Badia, J. Labarta. eNANOS Grid Resource Broker. P.M.A. Sloot et al. (Eds.): EGC 2005, LNCS 3470, Amsterdam, June 2005, pp. 111-121
[14] Unicore Web Site. http://www.unicore.eu/
[15] I. Foster, C. Kesselman, J. Nick, and S. Tuecke. Grid Services for Distributed System Integration. IEEE Computer, pages 37–46, June 2002.
[16] Legion Web Site, http://www.legion.virginia.edu/
[17] Condor Web Site, http://www.cs.wisc.edu/condor/
[18] Nimrod Web Site, http://www.csse.monash.edu.au/~davida/nimrod/
[19] Mpich-G2 Web Site, http://www3.niu.edu/mpi/
[20] M. P. Thomas, J. R. Boisseau, Building Grid Computing Portals: The NPACI Grid Portal Toolkit
[21] APBS Tutorial: http://apbs.sourceforge.net/doc/tutorial/
[22] Cog Kit: http://www.globus.org/cog/java/
[23] Survey of Major Tools and Technologies for Grid-enabled Portal Development. Xiaoyu Yang, Martin T. Dove, Mark Hayes, Mark Calleja, Ligang He, Peter Murray-Rust. Proceedings of the UK e-Science All Hands Meeting 2006, © NeSC 2006, ISBN 0-9553988-0-0
[24] Ian Foster and Carl Kesselman. Globus: A metacomputing infrastructure toolkit. International Journal of Supercomputer Applications, 11(2):115–128, 1997.
[25] GridPort Web Site: http://gridport.net/main/
[26] J. Novotny “The Grid Portal Development Kit” Concurrency and Computation: Practice and Experience, Special Issue: Grid Computing Environments, vol. 14, no. 13-15
[27] Common Component Architecture Forum Web Site: http://www.cca-forum.org/
[28] http://www.globus.org/wsrf/
[29] http://doesciencegrid.org/projects/GPDK/
[30] http://www.grid-support.ac.uk/
[31] http://www.collab-ogce.org/ogce/index.php/Main_Page
[33] http://portals.apache.org/jetspeed-1/
[34] http://ralyx.inria.fr/2006/Raweb/oasis/uid0.html
[35] http://www.opengroup.org/projects/soa/
[36] Steve Mock, Mary Thomas, and Gregor von Laszewski. The Perl Commodity Grid Toolkit. Grid Computing environments: Special Issue of Concurrency and Computation: Practice and Experience, 14(13-15):1085–1095, 2002.
[37] https://hotpage.npaci.edu/
[38] Mary Thomas, Steve Mock, and Jay Boisseau. Development of web toolkits for computational science portals: The NPACI HotPage. In 9th IEEE International Symposium on High Performance Distributed Computing, pages 308–309, 2000.
[39] Jason Novotny. The Grid Portal Development Kit. Grid Computing environments: Special Issue of Concurrency and Computation: Practice and Experience, 14(13-15):1129–1144, 2002.
[40] Gregor von Laszewski, Ian Foster, Jarek Gawor, and Peter Lane. A Java Commodity Grid Kit. Concurrency and Computation: Practice and Experience, 13(8-9):643–662, 2001.
[41] J. Novotny “The Grid Portal Development Kit” Concurrency and Computation: Practice and Experience, Special Issue: Grid Computing Environments, vol. 14, no. 13-15
[42] http://sara.unile.it/grb/
[43] Giovanni Aloisio, Massimo Cafaro, Euro Blasi, Lucio de Paolis, and Italo Epicoco. The GRB library: Grid computing with Globus in C. In 9th International Conference, HPCN Europe 2001, volume 2110 of Lecture Notes in Computer Science, pages 133–140. Springer-Verlag, 2001.
[44] http://www.gridsphere.org/
[45] J. Novotny “Developing grid portlets using the GridSphere portal framework”, IBM developerworks, 2004.
[46] Liferay: http://www.liferay.com
[47] A. Akram,D. Chohan,X.Wang,X.Yang and R. Allan “A Service Oriented Architecture for Portals using Portlets”, All Hands On Meeting, 2005
[48] The eXo platform: http://www.exoplatform.com
[49] B. Mestrallet, T. Nguyen et al “eXo Platform v2, Portal, JCR, ECM, Groupware and Business Intelligence”. Available: http://www.theserverside.com/ articles/article.tss?l = eXoPlatform
[50] StringBeans: http://www.nabh.com/projects/sbportal
[51] X. Yang, D. Chohan, X. Wang and R. Allan “A Web portal for National Grid Service” Presented at GridShpere and Portlets workshop, 03 March, 2006, eScience Institute, Edinburgh
[52] uPortal project: http://www.uportal.org/
[53] Pluto: http://portals.apache.org/pluto/
[54] Jetspeed-2: http://portals.apache.org/jetspeed-2/
[55] IBM WebSphere Portal: http://www-306.ibm.com/software/genservers/portal/
[56] P. Kacsuk, G. Sipos, “Multi-Grid, Multi-User Workflows in the P-GRADE Grid Portal”, Journal of Grid Computing, Springer Science + Business Media B.V., 2005.
[57] Introduction to JSR 168 http://developers.sun.com/prodtech/portalserver/ reference/techart/jsr168/
[58] WSRP Web Services for Remote Portlets http://www.oasisopen.org/committees/ tc_home.php?wg_abb rev=wsrphttp://www.oasis-open.org
[59] P-GRADE grid portal http://www.lpds.sztaki.hu/pgportal/
[60] SAKAI VRE demonstrator http://tyne.dl.ac.uk/Sakai/
[61] GridLab: http://www.gridlab.org
[62] Todd Tannenbaum, Derek Wright, Karen Miller, and Miron Livny. Condor – a distributed job scheduler. In Thomas Sterling, editor, Beowulf Cluster Computing with Linux. The MIT Press, 2002.
[63] David Abramson, Jonathan Giddy, and Lew Kotler. High performance parametric modeling with Nimrod/G: Killer application for the global Grid. In 14th International Parallel and Distributed Processing Symposium, pages 520 – 528, May 2000.
[64] David Abramson, Rok Sosic, Jonathan Giddy, and B. Hall. Nimrod: A tool for performing parametrised simulations using distributed workstations. In 4th IEEE International Symposium on High Performance Distributed Computing, pages 112–121, August 1995.
[65] Nicholas T. Karonis, Brian Toonen, and Ian Foster. MPICH-G2: A Gridenabled implementation of the Message Passing Interface. Journal of Parallel and Distributed Computing (JPDC), 63(5):551–563, 2003.
[66] Dietmar W. Erwin and David F. Snelling. UNICORE: A Grid computing environment. In 7th International Euro-Par Conference, volume 2150 of Lecture Notes in Computer Science, pages 825–834. Springer-Verlag, 2001.
[67] M. Romberg “The UNICORE architecture: seamless access to distributed resources”. Proceedings of the 8th IEEE International Symposium on High performance Distributed Computing 1999
[68] Ian Foster and Nicholas T. Karonis. A Grid-enabled MPI: Message passing in heterogeneous distributed computing systems. In Proceedings of SC’98. ACM Press, 1998.
[69] MyGrid project: http://www.mygrid.org.uk/
[70] Novotny, J., Tuecke, S., Welch. V. An Online Credential Repository for the Grid: MyProxy. Proceedings of the Tenth International Symposium on High Performance Distributed Computing (HPDC-10), IEEE Press, August 2001. Project website last accessed on 7/1/02 at: http://www.ncsa.uiuc.edu/Divisions/ACES/MyProxy.
[71] www.sura.org/suragrid/
[72] https://gridportal.sura.org/
[73] Beowulf site: http://www.beowulf.org/overview/index.html
[74] Rocks site: http://www.globus.org/grid_software/packaging/rocks.php
[75] G. Allen, G. Daues, I, Foster et al “The Astrophysics Simulation Collaboratory Portal: A science Portal Enabling Community Software Development” Proceedings of the 10th IEEE InternationalSymposium on High performance Distributed Computing 2001
[76] N. A. Baker, D. Sept, M. J. Holst, and J. Andrew McCammon. The adaptive multilevel finite element solution of the poisson-boltzmann equation on massively parallel computers. IBM Journal of Research and Development, 45:427–438, 2001.
[77] Jacobo Tarrío Barreiro, Diseño e implementación de un portal basado en tecnologías Grid para el acceso a recursos de supercomputación, Universidade da Coruña, 2003.
[78] GridGain http:// www.gridgain.org/
[79] Jeffrey Dean and Sanjay Ghemawat “MapReduce: Simplified Data Processing on Large Clusters” USENIX Association OSDI ’04: 6th Symposium on Operating Systems Design and Implementation 137.
[80] Rob V. van Nieuwpoort, Jason Maassen, Gosia Wrzesinska, Thilo Kielmann, and Henri E. Bal. Adaptive load balancing for divide-and-conquer grid applications. Journal of Supercomputing, 2006.
[81] M.H.J. Nijhuis. Divide-and-conquer barnes-hut implementations. Master's thesis, Faculty of Sciences, Division of Computer Science, Vrije Universiteit, Amsterdam, The Netherlands, May 2004.
ISSN 1666-1680
http://www.cyta.com.ar -
Recibido el: 06-08-2008; Aprobado el:14-09-2008
Volúmen:07
Número:4
Artículo:1
Buenos Aires, 15-10-2008
Ver Ficha:[Artículo]
Ver Ficha Autor/a:
[Sofia, Albert Osiris ][Casas, Sandra Isabel ]Traducir el artículo:[Translate]
(Ô_Ô) Recomendar el artículo por: Correo / facebook / Twitter / Google+ / WhatsApp /