Finanzas
Desvendando el Termómetro de insolvencia de Kanitz
José Roberto Kassai y
Silvia Kassai
Resumen
El análisis del balance a través de indicadores contables es enriquecido
por la existencia de modelos predictivos, estructurados a parir de un
conjunto de informaciones ponderadas de acuerdo con criterios estadísticos.
Este es el caso de los modelos de previsión de insolvencia.
El termómetro de insolvencia de Kanitz, utilizado para prever la
insolvencia de las empresas, fue uno de los modelos pioneros en Brasil en la
década de los años 70. al divulgar su modelo, KANITZ no explica como llegó a
la fórmula de cálculo, diciendo que se trata de una herramienta estadística.
El objetivo de este trabajo es justamente mostrar las herramientas
estadísticas utilizadas por el autor, de una forma simple y sin los rigores
de las formulaciones matemáticas. Se trata del análisis discriminante, una
técnica que permite realizar cálculos de regresión lineal con variables no
numéricas.
Mostramos, a través de cinco pasos básicos, como se monta un modelo
propio de previsión de insolvencia. Para eso, desenvolvemos un caso práctico
utilizando los recursos de cálculo de las conocidas planillas electrónicas.
Pretendemos, con esto, despertar al lector para modelos más recientes y
sofisticados, e incentivarlos a desarrollar sus propios modelos, no
solamente restringidos al análisis de crédito, sino también aplicables en
cualquier otra área del planeamiento empresarial, desmitificando la idea de
que solo con profundos conocimientos estadísticos se puede obtener dichos
modelos.
1
PRESENTACIÓN
El análisis de balances a través de indicadores contables ha sido
desarrollado en el medio académico gracias a la integración con la comunidad
empresarial. El campo de esos indicadores es amplio y la posibilidad de
crear nuevas fórmulas de acuerdo con las necesidades específicas tiene como
límite la experiencia y la creatividad de cada profesional.
Para que el analista no se sienta perdido frente a un gran número de
índices, cocientes, indicadores, muchas veces repetitivos y hasta muchas
veces contradictorios, esos análisis son dispuestos en grupos o modelos
específicos que buscan verificar la situación de una determinada empresa
sobre los más variados enfoques.
Los análisis tradicionales están dispuestos en grupos de indicadores que
buscan evaluar las situaciones de liquidez, endeudamiento, rentabilidad y
apalancamiento, retorno de la inversión, estructura de los activos, calidad
de los pasivos, etc.
Otros análisis se componen de modelos con capacidad predictiva,
estructurados a partir de una canasta de informaciones y ponderada de
acuerdo con criterios estadísticos. Es ele caso del modelo de previsión de
insolvencia elaborado por KANITZ y que es el foco de este estudio.
Al divulgar su modelo, KANITZ no explica como llegó a la formula de cálculo, diciendo que se trata de una herramienta estadística.
“Para calcular el factor de insolvencia…usamos una combinación de
índices, ponderados estadísticamente....Se trata de una ponderación
relativamente compleja…”[1]
IUDÍCIBUS, en sus estudios de análisis de balances, también relata el hecho:
“Stephen C. Kamiz…construyó el termómetro de insolvencia…Por otro lado,
no reveló la metodología empleada para construir el termómetro”[2].
El objetivo del presente trabajo es justamente desmitificar esa
herramienta estadística[3], de forma simple y sin los rigores de las
formulaciones matemáticas. Para eso, iremos a desarrollar un caso práctico
utilizando los recursos de la conocida planillas electrónicas.
Pretendemos, con esto, motivar al lector hacia los modelos más recientes
y sofisticados y hasta incentivarlo a desarrollar sus propios modelos, no
solamente acotados al análisis de crédito, sino aplicables en cualquier otra
área del planeamiento empresarial.
2 EL MODELO DE
PREVISIÓN DE FALENCIA DE KANITZ.
El profesor Srephenn Charles Kanitz, del Departamento de Contabilidad de
LA Facultad de Economía y Administración de la Universidad de Sao Paulo
(FEA/USP), fue responsable, durante mas de 20 años, por la elaboración del
análisis económico y financiero de las 500 Mejores y Mayores empresas
brasileras editada por loa Revista Exame[4]. Fruto de su trabajo junto a las
empresas y el de su investigación, elaboró un modelo de previsión de
falencias, también conocido como factor de insolvencia.
Este factor es obtenido a partir de informaciones de balances contables
de empresas a través del cálculo de una fórmula “mágica”, a saber:
F. Insolvencia = 0.05X1+ 1.65X2 +
3.55 X3 +-1.06X4 – 0.33X5
Donde
![]()
![]()
![]()
![]()
![]()
Luego del cálculo, se obtiene un número denominado de Factor de
Insolvencia que determina la tendencia de una empresa a fallar o no. Para
facilitar, el autor creo una escala llamada de Termómetro de Insolvencia,
indicando tres situaciones diferentes Solvente, Penumbra e Insolvente, a
saber:
|
Termómetro de Insolvencia de KANITZ |
|
|
7 5 4 3 2 1 0 |
SOLVENTE |
|
-1 -2 -3 |
PENUMBRA |
|
-4 -5 -6 -7 |
INSOLVENTE |
Los valores positivos indican que la empresa está en una situación buena
o “solvente”, si fuese menor a -3 la empresa se encuentra en una situación
mala o “insolvente” y que podrá llevarla a la quiebra. El intervalo
intermedio, de 0 a -3, llamada “penumbra” representa a un área en que el
factor de insolvencia no es suficiente para analizar el estado de la
empresa, pero inspira cuidados.
Una empresa que presenta un factor de insolvencia positivo, tiene menor
probabilidad de ir hacia el fracaso y esa posibilidad disminuirá a medida
que el factor positivo fuese mayor. Al contrario, cuanto menor fuese el
factor negativo mayores serán las chances de la empresa terminar sus
actividades.
En aquella época, inicio de la década del 70, KANITZ aplicó su modelo en
las 500 Mayores y Mejores empresas brasileras. La empresa seleccionada como
la mejor del año presentaba un factor de insolvencia igual a “10”, en tanto
que otra con factor igual a “-2.6” pidió concurso de acreedores al año
siguiente, con un factor de insolvencia igual a “-7”.
En Brasil, el modelo de KANITZ fue uno de los precursores (1972). En los
EUA Edward ALTMAN ya exploraba esa técnica (1930). Actualmente, otros
investigadores brasileros ya desarrollaron modelos semejantes y más
actualizados, como ELIZABETSKY, MATIAS e PEREIRA. Las fórmulas de estos
otros modelos están demostradas a continuación.
- Modelo de ALTMAN:
Factor =
1,84-0,51X1+0,7X2+6,32X3+0,71X4+0,53X5
Donde:
X1 = (Activo Circulante – pasivo Circulante) / Activo Total
X2 = Reservas y Ganancias Retenidas / Activo Total
X3 = Activo Total
X4 = Patrimonio Neto / Exigible Total
X5 = Ventas / Activo Total
Análisis: El punto Crítico es “cero”
- Modelo de ELIZABETSKY:
Factor =
1,93X1-0,2X2+1,02X3-1,33X4-1,12X5
Donde:
X1 = Ganancia Neta / Ventas
X2 = Disponible / Activo Permanente
X3 = Cuentas a Recibir/ Activo Total
X4 = Stock / Activo Total
X5 = Pasivo Circulante / Activo Total
Análisis: El punto Crítico es “0.5”
- Modelo de MATIA:
Factor =
23,792X1-8,26X2-9,868X3-0,764X4-0,535X5+9,912X6
Donde:
X1 = Patrimonio Neto/ Activo Total
X2 = Préstamos Bancarios / Activo Circulante
X3 = Proveedores/ Activo Total
X4 = Activo Circulante / Pasivo Circulante
X5 = Ganancia Operativa / Activo Total
X6= Disponible / Activo Total
Análisis: El punto Crítico es “cero”
- Modelo de PEREIRA:
Factor =
0,722-5,124X1+11,016X2-0,342X3-0,048X4+8,605X5+0,004X6
Donde:
X1 = Documentos Descontados/ Documentos a Recibir
X2 = Stock Final / Costo de las Mercaderías Vendidas
X3 = Proveedores/ Ventas
X4 = Stock Medio / Costo de las Mercaderías Vendidas
X5 = Exigible Total / (Ganancia Neta + 10% Inmovilizado medio + Saldo
Deudor de la Corrección Monetaria.)
Análisis: El punto Crítico es “cero”
Todos estos modelos de previsión de insolvencia fueron desarrollados a
partir de una determinada muestra colectada en sus respectivas épocas. El
modelo de KANITZ, por ejemplo, no tendría hoy el mismo grado de precisión
previsto en la época de su desarrollo.
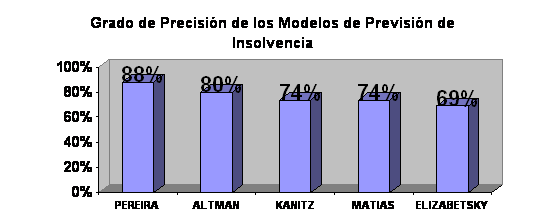
PEREIRA[5] apuró el grado de precisión de estos modelos comparando las
empresas clasificadas correctamente con las informaciones reales obtenidas
en muestras de empresas solventes e insolventes. Su modelo fue el que obtuvo
mejor índice de acierto, 90% para las empresas solventes y 86 % para las
empresas insolventes.
Vea el gráfico a seguir con el grado de
precisión, el de aciertos, (medio) de esos modelos que adaptamos a partir
del estudio de PEREIRA:
Esos modelos son desarrollados a través de una técnica estadística
denominada de análisis discriminante. Su uso, bastante difundido en otros
países, solo ahora comienza a ser difundido en Brasil.
3. Instrumental Estadístico Utilizado: El Análisis
Discriminante.
El análisis discriminante, también llamado análisis del factor
discriminante o análisis discriminante canónico, es una técnica estadística
desarrollada a partir de los cálculos de regresión lineal y, al contrario de
esta, permite resolver problemas que contengan no solamente variables
numéricas, sino también variables de naturaleza cualitativa, como es en el
caso de empresas “solventes” e “insolventes”.
¿Pero cómo realizar cálculos matemáticos con esas variables “no
numéricas”?. Es simple, basta atribuir un número cualquiera a esas
variables. Por ejemplo, empresa no solvente es igual a “1”, y empresas
solventes es igual a “2”. Con este artificio, transformamos aquel problema
en un problema simple de regresión lineal. Por lo tanto, el análisis
discriminante es una sofisticación de los tradicionales cálculos de
regresión lineal.
Al imaginarnos dos puntos distintos, conseguimos fácilmente pasar una
recta entre los mismos y, como sabemos, ésta puede ser representada por una
ecuación matemática del tipo “y=mx + b”. Si quisiéramos estimar otro punto
cualquiera de esta recta, basta calcularlo a partir de esta ecuación.
En otra situación en que hay diversos puntos, y no dispuestos en línea
recta, también es posible determinar una recta y la respectiva ecuación
lineal y, obviamente, solo tendrá valor si esos puntos no estuviesen muy
dispersos. Este grado de dispersión es medido a través del cálculo de
correlación, o “R-Cuadrado”[6].
En los modelos de previsión de insolvencia, el análisis discriminante se procesa de la siguiente manera:
- Seleccionar dos grupos de empresas, solventes no solventes.
- Seleccionar los respectivos indicadores contables de esas empresas.
- Atribuir números a las variables no numéricas.
- Obtener la ecuación lineal a través de los cálculos de regresión, que es la base del modelo de previsión de insolvencia.
- El grado de precisión del modelo puede ser medido comparándose la
clasificación de las empresas a partir de la ecuación de regresión, con la
clasificación original previamente establecida. Si el grado de precisión
fuese muy bajo, es necesario sustituir los indicadores contables
seleccionados al incorporar nuevos.
El proceso para la construcción de un modelo de previsión de insolvencia
es relativamente simple. La calidad de un modelo es evaluada por su grado de
precisión y por la habilidad de su autor en la selección de cuales y cuantos
indicadores contables utilizar. La idea es alcanzar un grado de precisión lo
mayor posible, próximo al 100% y con el menor número posible de indicadores
o información.
Esta optimización es alcanzada a través del feeling del autor e de las
innumerables simulaciones de inclusión o exclusión de indicadores, del
análisis de correlación entre los mismos, Test de hipótesis, hasta llegar a
un grado de precisión que se juzgue adecuado. Este proceso solo es
practicable utilizando recursos de procesamiento electrónico de datos
KANTITZ desarrolló su modelo, en su época, a través de “tarjetas
perforadas”, hoy, disponemos de un amplio número de software estadístico[7].
4 CONSTRUCCIÓN DE UN MODELO A TRAVÉS DE LA PLANILLA
EXCEL
Para demostrar la técnica de análisis discriminante en la construcción de modelos de previsión de insolvencia, vamos a desarrollar un caso práctico a través de la planilla electrónica Excel[8].
Desarrollamos cinco pasos básicos para la construcción del nuestro propio modelo a saber:
- 1º Paso: obtener los datos y montar el problema
- 2º Paso: efectuar el cálculo de regresión lineal y definir la “función o ecuación discriminante.”
- 3º Paso: construir una columna llamada “score discriminante” y calcular el “punto de corte”.
- 4º Paso: analizar el “grado de precisión” del modelo.
- 5º Paso: construir el “termómetro de insolvencia”.
Considerando las simplificaciones necesarias para una demostración
propuesta en este trabajo, vayamos a desarrollar estos pasos, a través de un
caso simplificado.
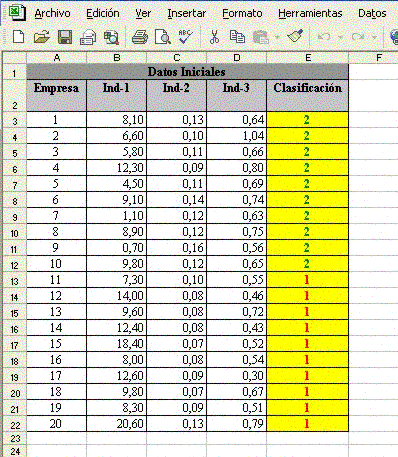
El señor Zezinho, Resolvió, montar su propio termómetro de insolvencia. Para ello, obtuvo una muestra de casos reales compuesta de 20 empresas, siendo 10 empresas consideradas “solventes” y 10 empresas que fallidas, consideradas “insolventes”. Para cada una de estas empresas, el había seleccionado, inicialmente, un gran número de indicadores contables, pero después de algunas reflexiones utilizando toda su experiencia en el análisis de crédito y balances, como así también nociones básicas de estadística, redujo a solamente 3 indicadores contables. Vea el cuadro con la información:
|
Datos Iniciales |
||||
| Empresa | Ind-1 | Ind-2 | Ind-3 | Clasificación |
| 1 | 8.1 | 0.13 | 0.64 | Solvente |
| 2 | 6.6 | 0.10 | 1.04 | Solvente |
| 3 | 5.8 | 0.11 | 0.66 | Solvente |
| 4 | 12.3 | 0.09 | 0.80 | Solvente |
| 5 | 4.5 | 0.11 | 0.69 | Solvente |
| 6 | 9.1 | 0.14 | 0.74 | Solvente |
| 7 | 1.1 | 0.12 | 0.63 | Solvente |
| 8 | 8.9 | 0.12 | 0.75 | Solvente |
| 9 | 0.7 | 0.60 | 0.56 | Solvente |
| 10 | 9.8 | 0.12 | 0.65 | Solvente |
| 11 | 7.3 | 0.10 | 0.55 | Insolvente |
| 12 | 14.0 | 0.08 | 0.46 | Insolvente |
| 13 | 9.6 | 0.08 | 0.72 | Insolvente |
| 14 | 12.4 | 0.08 | 0.43 | Insolvente |
| 15 | 18.4 | 0.07 | 0.52 | Insolvente |
| 16 | 8.0 | 0.08 | 0.54 | Insolvente |
| 17 | 12.6 | 0.09 | 0.30 | Insolvente |
| 18 | 9.8 | 0.07 | 0.67 | Insolvente |
| 19 | 8.3 | 0.09 | 0.51 | Insolvente |
| 20 | 20.6 | 0.13 | 0.79 | Insolvente |
Después de obtener los datos, la primera etapa es sustituir las variables “no numéricas” por valores numéricos, a fin de poder dar continuidad a los cálculos estadísticos. Con este artificio, al valor de “insolvente” le atribuimos un número “1” y “2” para “solvente”, a saber:
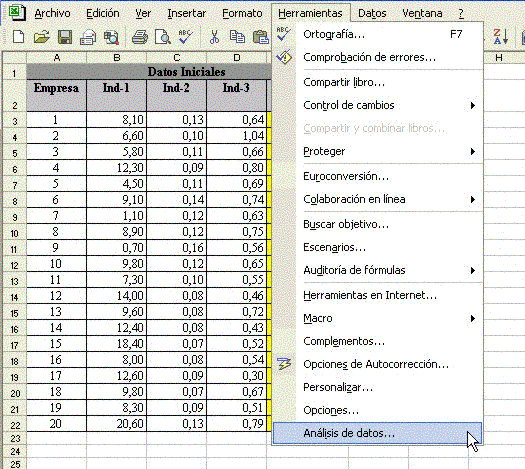
Una vez estructurados los datos en forma de planilla, vamos a realizar el cálculo de regresión lineal a través de la función “Herramientas / Análisis de datos/ Regresión” de la planilla electrónica Excel, a saber:
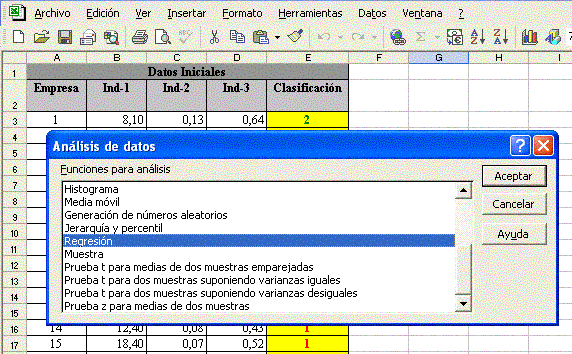
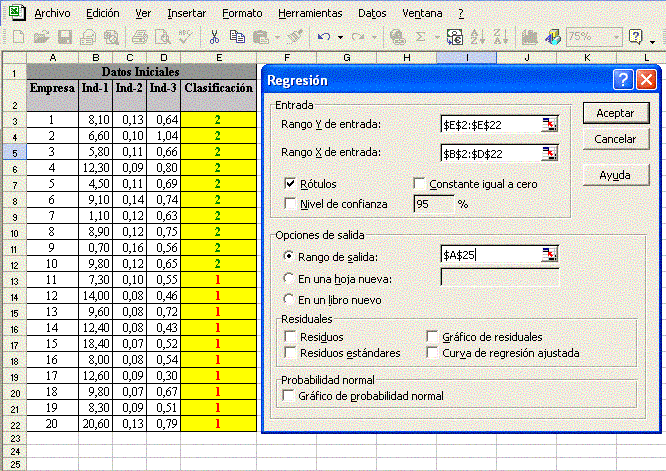
Seguido, hacer clic en aceptar y el aplicativo presentará los resultados de la regresión lineal:
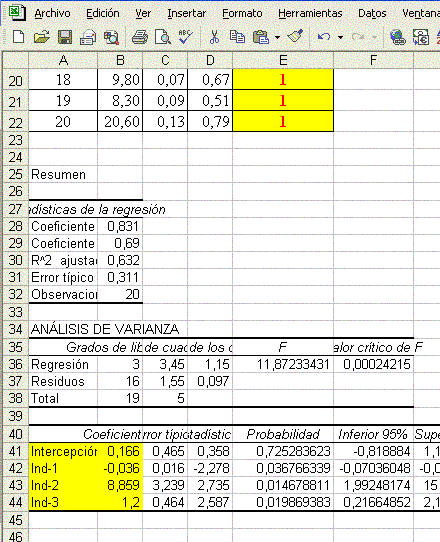
En base a los coeficientes obtenidos en la regresión, podemos crear la
“función discriminante”, esta es, la ecuación de regresión, a saber:
Y = 0,846 - 0,045(Ind1) +
0,748(Ind2) + 1,562(Ind3)
En el caso de que la ecuación presente un índice de error muy grande, la
base de datos debería ser alterada hasta llegar a un resultado aceptable.
Este análisis es hecho a través de los “R-cuadrado” calculado
automáticamente en la planilla de Excel.
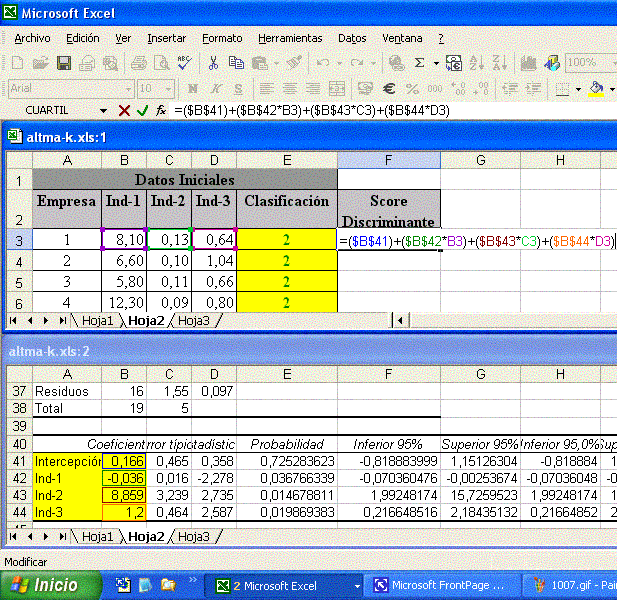
Muy bien, en principio esta fórmula representa a nuestro modelo de
previsión de insolvencia. Mientras tanto, aún falta analizar su grado de
precisión y para ello precisamos calcular el “Score Discriminante” y el
“Punto de Corte”[9].
Llamamos de “Score Discriminante” a otra columna con los valores
calculados en base a la función discriminante para cada una de las 20
empresas. El “Punto de Corte”. Es obtenido a través de la media aritmética
de las medias de los Scores Discriminantes de cada grupo de empresas, a
saber:
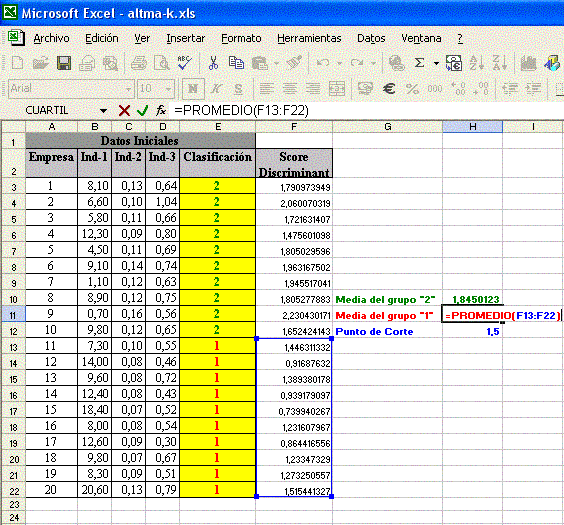
El punto de corte de “1,5” sirve de parámetro para clasificar a las
empresas de ese modelo. Debajo de este Store serán clasificadas las empresas
del grupo “1” (insolventes) y por sobre el valor de 1,5 las empresas del
grupo “2” (solventes). La próxima etapa, por lo tanto, es reclasificar las
20 empresas seleccionadas en base de este modelo y, comparándose con la
clasificación original, determinar su “grado se precisión”. Observe en la
siguiente figura:
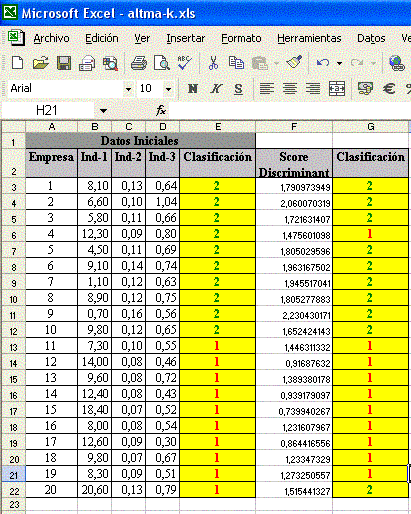
Comprobándose que en la clasificación obtenida a partir de nuestro modelo
de previsión de insolvencia con la clasificación original de la muestra de
empresas, constatamos que hubo apenas dos clasificaciones equivocadas, esto
indica que nuestro modelo presenta un gado de precisión del 90 %, lo que es
considerado como “optimo”.
Una vez obtenida un grado d precisión aceptable, el modelo está aprobado.
Si esto no fuese así, tendríamos que simular nuevos datos, empresas,
indicadores hasta llegar a un nivel aceptable.
Siguiendo el modelo de KANITZ, podemos también nosotros creas un “termómetro de insolvencia”. O sea, una escala ilustrativa para la clasificación de las empresas. Para esto, precisamos calcular el desvío padrón de los score discriminantes de cada grupo, lo que es una tare muy simple usando las funciones del Excel, a saber:
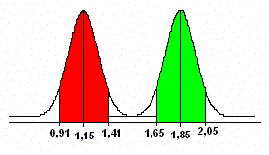
Considerándose la amplitud de un desvío estándar para cada uno de los
grupos de empresas, se puede notar un intervalo (1,45 a 1,61) que está fuera
de esta área y que KANITZ llamó en su modelo de área de “penumbra”, o sea,
una empresa clasificada en esta área está en una situación indefinida y,
probablemente, inspira atención.
Estadísticamente, significa que el modelo no tiene base para afirmar ninguna clasificación en este intervalo.
Finalmente, ahora podemos diseñar nuestro “Termómetro de Insolvencia”,
inclusive considerando un área de “penumbra”, tal el ejemplo de KANITZ.
|
Termómetro de Insolvencia de KANITZ |
|
|
2,05
1,85
1,65 |
SOLVENTE |
|
1,64
1,42 |
PENUMBRA |
|
1,41
1,15
0,91
|
INSOLVENTE |
El punto crítico de nuestro modelo es “1,45”. Una empresa clasificada por
debajo de este valor deberá estar en una mala situación, de insolvencia y
que, probablemente, irá a fallar si se mantienen las condiciones actuales.
Por el contrario, una empresa clasificada por arriba de “1,61”, y cuanto mas
alejada (por arriba) esté de este punto, menores serán sus posibilidades de
fallar algún día.
5 Comentarios Finales
El análisis discriminante así como otros métodos cuantitativos basados en
estadística, que ya están bastante difundidos en otros países, solo ahora
comienza a ser empleados en Brasil. En nuestra opinión, esto se debe al
conocimiento restringido en estadística de la media de nuestros
profesionales. Los tiempos del auge de la inflación vividos en los últimos
años y de la turbulenta economía también han contribuido para ello,
dificultando y desmotivando a los profesionales para el uso de estos métodos
cuantitativos en la gestión empresarial.
Esperamos haber contribuido a despertar en los lectores el interés por el
uso de las técnicas estadísticas, en especial hacia el análisis
discriminante y alertamos para el hecho de que, a pesar de la “perfección”
matemática de estos modelos predictivos, aún no substituyen al ser humano en
sus decisiones. Es más, ni siquiera el propio ser humanos es capaz de prever
el futuro con certeza[10].
La tendencia es que esos modelos sean utilizados so solamente como una
“bola de cristal” para prever el futuro, pero sí principalmente como
instrumentos de evaluación del riesgo empresarial. Una empresa señalada como
insolvente por uno de estos modelos puede que realmente no fracase, pero
apostar en ella envuelve un nivel mayor de riesgo y por ello el retorno
pretendido tiene que superior.
De esta forma, nos debemos rodear de todos los recursos que nos ayuden al
proceso de toma de decisiones en un ambiente empresarial. Los buenos
profesionales, que también dominan los métodos cuantitativos, seguramente
estarán aventajando a los demás.
[1] Kanitz, Stephen Charles. Como prever falencias de empresas. Artibo publicado originalmente en la revista Exame de diciembre de 1974, pag. 95 a 102
[2] IUDICIBUS, Sérgio de. Análise de Balanços. Sao Paulo: Atlas, 7º ediçao, pag. 129.
[3] La técnica estadística utilizada es el ANÁLISIS DISCRIMINANTE, a ser tratada en este trabajo
[4] Actualmente este trabajo es efectuado por la Fundación Instituto de Pesquisas Contabeis, Aturiais e Financieras (FIPECAFI), bajo la coordinación de los profesores L. Nelson de Carvalho e Ariovaldo dos Santos, también del Departamento de Contabilidad de FEA/USP.
[5] SILVA, José Pereira da. Administraçao de crédito e previao de
insolvencia. Sao Paulo:Atlas, 1983
[6] El R-Cuadrado (o R2) varía en una escala de 0 a 1 y cuanto mas
próximo a “1”, mejor es la capacidad predictiva de la ecuación.
Inversamente, si el grado de correlación fuese fuera próxima a “0” la
ecuación obtenida no podrá ser utilizada con la misma eficiencia. En este
caso, es recomendable alterar la base de los datos hasta conseguir una
ecuación adecuada. Mayores informaciones podrán ser obtenidas en un buen
libro de estadística o en el Laboratorio de Contabilometría de Fipecafi
–FEA/USP.
[7] Los programas conocidos por “Redes Neuronales” también son utilizados
en el análisis de previsión de solvencia de las empresas y fueron
desarrollados a partir de los conceptos de análisis discriminante. Las
ecuaciones son generadas también por medio de regresión no-lineal o
múltiples y las variables cualitativas son tratadas libremente, sin la
necesidad de convertirlas en variables numéricas.
[8] Utilizamos la última versión del aplicativo Microsoft Excel. El mismo puede ser obtenido con versiones más antiguas u otras planillas electrónicas como Lotus, Works, Etc.
[9] Existen otras técnicas estadísticas para “refinar” el cálculo de punto de corte y perfeccionar el análisis discriminante, por ejemplo el cálculo de la Distancia Euclidiana. Distancia de Mahalnobis, análisis multivariante, etc. En nuestro caso, el punto de corte refinado es igual a 1,45. Mayores informaciones podrán ser obtenidas en el Laboratorio de Conabilometría de la Fipecafi –FEA/USP.
[10] ---a propósito, la empresa que mencionamos anteriormente en este trabjao como la campeona entre las 500 mejores e mayores por la Revista Exame/74, clasificada como empresa muy solvente por el Termómetro de Knitz, después de 20 años tuvo que ser vendida para evitar la quiebra.