| 4.1. MODELOS CONCEPTUALES Un modelo es una descripción
capaz de ser comunicada y que busca:
Comunicar un cierto
aspecto (visión),
de una parte de la
realidad (sistema),
con cierto grado de
detalle (abstracción),
conforme perseguido por
alguien (autor del modelo),
con el objetivo de
servir a los propósitos del usuario.
Sowa Argumenta que el
conocimiento sobre alguna cosa es la
habilidad de formar un modelo mental que
represente esta cosa, como así también
las aciones que ella puede realizar o se
pueden realizar sobre ella. Cuando el
individuo verifica acciones sobre este
modelo él puede predecir las
implicaciones que estas acciones tendrán
sobre el mundo real.
Según Sowa, al
relacionar las cosas entre sí y al
pensar de forma estructurara sobre ellas,
podremos describir el funcionamiento de
un sistema, y esto debería ser el
propósito de todo modelo.
Los modelos pueden
tener diferentes clases de estructuras;
pero las clases más comunes son: la
verbal, la simbólica y la matemática.
En los modelos
verbales, las variables y sus relaciones
se funden en forma de prosa. El manual de
procedimientos, el manual de
organización o la Lista de eventos, que
describiremos próximamente (ver 4.2.1. la modelización de
las funciones del sistema), son ejemplos de modelos
verbales.
Los modelos simbólicos
generalmente son más específicos que
los verbales; Ellos representan un puente
útil en el proceso de simbolizar un
modelo verbal; por ejemplo, sería muy
conveniente que en un manual de
organización se incluya un organigrama
(esquema para modelizar la estructura de
la empresa). La mayoría de los modelos
simbólicos se usan para aislar variables
y sugerir las direcciones de las
relaciones, como lo veremos mas adelante
al describir los Diagramas De Flujo de
Datos y el Modelo Relacional de
Datos, pero pocos se diseñan para
dar resultados numéricos específicos.
El mayor beneficio de los modelos
simbólicos está en la representación
gráfica de los hechos a través de
cuadros o nodos; y es así que el
fenómeno se despoja de lo que no es
esencial, permitiendo al investigador
(observador) entender el conjunto y
seleccionar las relaciones a examinar..
Algunos modelos pueden
combinar componentes icónicos y
análogos; como por ejemplo los flujogramas
(ver 4.5. flujogramas), dichos diagramas por lo
general tienen carácter cualitativo pero
pueden convertirse en modelos simbólicos
cuantitativos muy exactos.
Un punto muy importante
de los modelos es el de saber como
probarlos, a fin de determinar su
valides; y estos tienen básicamente dos
formas de ser probados, una es la forma
prospectiva (contra el desempeño
futuro), y la otra es de forma es
retrospectiva (contra el desempeño
pasado); en éste último caso, o sea si
un modelo se prueba retrospectivamente,
es de vital importancia que los periodos
utilizados cubran las situaciones que tal
vez se encurte en el futuro.
Cuando un modelo no se
puede probar en forma prospectiva ni en
forma retrospectiva, el análisis de su
sensibilidad al error puede servir de
base para evaluarlo. Dicho análisis
consiste en determinar cuánto tienen que
bajar los valores de las variables del
modelo para que los medios mejores
especificados en dicho modelo tengan un
desempeño inferior al de un medio
alternativo. Después, utilizando el
juicio sobre la posibilidad de esta baja,
se puede hacer una evaluación parcial
del modelo.
Además de su utilidad
para evaluar medios; los modelos se
pueden utilizar heurísticamente, es
decir, para facilitar el descubrimiento.
Con frecuencia son un medio efectivo para
explorar la estructura asumida de una
situación determinada, y para descubrir
posibles cursos de acción que de otra
manera se pasarían por alto.
4.2. LA MODELIZACIÓN DE LAS
FUNCIONES DEL SISTEMA
4.2.1. LISTA DE
EVENTOS.
Las primeras
actividades de diseño de los sistemas
(ver cap1.1 que es un PI y 1.2 inicio de un PI), están especialmente
influenciadas por la naturaleza de los
requerimientos y éstos incluyen
principalmente descripciones en lenguaje
natural, que según lo visto en el
tópico anterior (4.1.); representan una
realidad dada e interpretada de
diferentes maneras según sea la visión
y la capacidad de abstracción, de cada
uno de los participantes del proyecto.
En el caso de que los
requerimientos, fuesen realizados en
forma oral o escrita en lenguaje natural,
es indispensable realizar un análisis
profundo del texto para poder entender en
detalle el o los significados de todos
los términos involucrados en el proyecto
(libres de contradicciones e
incongruencias). Luego esta lista
estructurada, en el diseño inicial,
será la base para la construcción de
las entidades y sus relaciones; y que
estarán representadas en los diagramas
de flujo de datos y en el modelo
relacional de datos.
TÉCNICA PARA EL
DISEÑO DE UNA LISTA DE EVENTOS
A continuación
presentamos una lista de reglas
empíricas que ayudarán a la
construcción, en forma estructurada, de
la lista de eventos.
- Elegir el nivel
apropiado de abstracción para
los términos.
Se debe
preferir, la utilización de,
palabras concretas a palabras
abstractas. Las palabras
concretas se refieren a objetos o
sujetos tangibles; el lector las
puede descifrar fácilmente,
porque se hace una clara imagen
de ellas asociándolas a la
realidad.
En cambio, las palabras
abstractas designan conceptos o
cualidades más difusos, y suelen
abarcar un número mayor de
acepciones. El lector necesita
más tiempo y esfuerzo para
captar su sentido, pues no hay
referentes reales.
Por lo tanto es muy importante el
escoger la acepción más
apropiada, entre las diversas
alternativas posibles.
Por ejemplo veamos los siguientes
términos:
El gerente del área de finanzas,
es quien autoriza las compras.
Es una oración demasiada
ambigua. Su principal dificultad
reside en el significado de compras.
Al tratarse de una palabra
bastante genérica, entran en
juego muchas acepciones
Compras se refiere a:
Si se considera en función del
tiempo, se refiere a: ¿compras
programadas, no programadas o
ambas?. Si se evalúa en función
del volumen, se refiere a:
¿grandes pedidos, a pedidos
pequeños o ambos?. En función
de su origen, involucra a: ¿las
importaciones o las de plaza
local?. Y en función del bien:
¿en insumos y/o bienes de
capital?.
¡Cuál de estos términos es el
correcto?; si el resto del texto
no ofrece la información
necesaria para sobre la
alternativa correcta; solo queda
la alternativa de hacer una
hipótesis de significado
genérica. Lo que significa
asumir un riesgo, que obviamente
no debería existir.
- Evitar el uso
de casos en lugar de conceptos
generales.
Es común
observar que los usuarios de los
sistemas de información, adoptan
términos más específicos de
los que verdaderamente son
necesarios. Por ejemplo, el
encargado de almacenes dice:
"necesito conocer a diario
la cantidad en existencia de
pastillas de frenos", El
término pastillas de frenos no
describe un concepto, sino una
instancia o componente del
concepto correcto, esto es, un
componente. Por lo tanto el
término debería ser insumos.
- Evitar las
expresiones vagas o indirectas.
Al usar rodeos,
se incurre en el riesgo de
expresar el significado de los
conceptos en términos de
referencias implícitas a otros
conceptos, en lugar de
referencias explícitas a los
mismos conceptos. Por ejemplo
cuando se dice: "mirá el
repuesto en la cajonera", en
vez de decir; "mirá las
cajoneras". La segunda
oración indica una clase
específica de entidad
(cajonera), mientras que la
primera se refiere a la misma
clase indicando una
interrelación con otra clase de
entidad (repuesto). Es así que
la segunda oración, "mirá
las cajoneras", permite una
clara clasificación de los
conceptos.
- Elegir un
estilo estandarizado de
enunciado.
Lo que se busca
con un modelo sintáctico es
lograr una comunicación buena y
eficaz. Idealmente, se debe
buscar elaborar enunciados que
respondan a algún estilo
estándar, en el caso de las
descripciones de los datos,
éstas deben ser frases
afirmativas, compuestas por hasta
cuatro elementos-llave, que son
el <sujeto>, el <verbo>,
el <objeto> y el <complemento>,
que pueden ser el instrumento o
el modificador. Estos
elementos-llave pueden estar
acompañados de otras palabras
como artículos, adjetivos, etc.;
por ejemplo:
El encargado
del sector ALMACENES verifica el PARTE
DE RECEPCIÓN con la SOLICITUD
DE COMPRA
Generará la
siguiente estructura-llave:
ALMACENES
verifica PARTE DE RECEPCIÓN
con SOLICITUD DE COMPRA
Donde ALMACENES
es el sujeto, verifica es el
verbo, PARTE DE RECEPCIÓN es
el objeto y SOLICITUD DE
COMPRA es el instrumento.
Considere que
una frase puede estar incompleta;
Por ejemplo:
ALMACENES emite
SOLICITUD DE COMPRA
En ella no hay
complemento.
También es
importante que los enunciados que
describen operaciones deben
utilizar, tanto como les sea
posible, estructuras sintácticas
no ambiguas (PRODUCTOS, en LISTA
DE PRODUCTOS o en STOCK),
similares a las de los lenguajes
de programación, como si,
condición, entonces, sino,
cuando, hacer, acción. Por
ejemplo: Si el monto es menor a
100 aprueba el pedido, sino eleva
el pedido a Gerencia Financiera.
- Verificar los
sinónimos y los homónimos.
Distintas
personas pueden dar el mismo
significado a diferentes cosas
(sinónimo) o diferentes
significados con las mismas
palabras (homónimos). En un
procedimiento de ventas pueden
encontrarse los siguientes
términos: Cliente, comprador,
usuario, parroquiano, y referirse
al mismo concepto (sinónimos) En
el caso de que el mismo término
sea utilizado, en diferentes
lugares, con significados
diferentes es considerado pues un
homónimo. Por ejemplo Para
finanzas el cliente es quien
compra un producto, mientras que
para Marketing el cliente, o
potencial cliente, es el usuario
del producto.
- Hacer
explícitas las referencias entre
términos.
Se debe evitar
cometer ambigüedades; es decir:
frases que puedan interpretarse
de dos o más maneras distintas.
Algunas ambigüedades surgen al
no especificar las referencias
entre los términos. La
ambigüedad puede provocar o un
doble sentido o una
incertidumbre.
En el caso de:
Recepción firma remito.
Cuál remito
firma, el original o alguna
copia.
O por ejemplo:
El jefe de compras se reúne con
cada uno de los proveedores en su
despacho.
En qué
despacho se reúnen, en el de
compras o en el de los
proveedores.
O en el caso
particular de nuestros archivos,
si contamos con dos archivos
PRODUCTO Y STOCK y ambos cuentan
con los mismos atributos: Código
del producto y Nombre del
producto y, STOCK se diferencia
por contar además con el
atributo Saldo del producto; Lo
que ocurre es que, probablemente
no sean dos entidades distintas
sino una sola entidad: PRODUCTOS
EN STOCK y que debería contener
a los atributos de ambas (ver 4.4. diseño de
relación uno a uno).
- Hacer un
Diccionario de Datos.
Como veremos
más adelante (ver 4.3. el diccionario
de datos),
ir confeccionando el diccionario
de datos, es una buena manera de
entender el significado de los
términos y de eliminar las
ambigüedades de los
requerimientos. Aunque, la
confección del diccionario de
datos, demande bastante tiempo es
fundamental su elaboración y
dejar de lado esta herramienta,
no se justifica en ningún caso.
Recuerde que puede utilizar
cualquier herramienta de
ingeniería de software para su
construcción.
4.2.2. EL
DIAGRAMA DE FLUJO DE DATOS
El Diagrama de Flujo
de Datos (DFD) es una
herramienta de modelización que permite
describir, de un sistema, la
transformación de entradas en salidas;
el DFD también es conocido con el nombre
de Modelo de Procesos de Negocios (BPM,
Business Process Model).
El objetivo del DFD es:
- Describir el
contexto del sistema,
determinando lo que ocurrirá en
cada una de las áreas de la
empresa, denominadas Entidades
externas, que participen de este
sistema;
- Detallar los
procesos a ser realizados;
- Enumerar los
archivos de datos necesarios, en
cada proceso;
- Definir los flujos
de datos, que participen en el
procedimiento.
En otras palabras, el
DFD permite representar de forma completa
el sistema de información, al relacionar
los datos almacenados en los archivos de
datos del sistema, con los procesos que
transforman a estos dados.
Una de las principales
características de este modelo es su
simplicidad, y se debe al hecho que son
solamente cuatro los símbolos utilizados
que representan a los elementos
(entidades externas, archivos, procesos y
flujos de información); con los cuales
se puede producir un esquema, que alcance
el nivel de detalle requerido por el
proyectista; y éste pueda ser
interpretado por todas las personas
involucradas en el proyecto, sin el
requerimiento de un conocimiento previo
de informática.
TÉCNICA DE
DISEÑO DEL DFD
En el diseño de un DFD,
como ya lo dijimos anteriormente, son
utilizados cuatro símbolos :
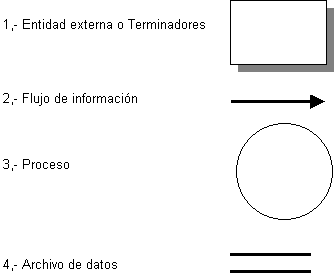
Figura 4.2.2.
Simbología del DFD Metodo Yourdon
1. Las, Entidades
externas, que pueden representar
a una persona, a un grupo de personas o,
a un sistema; Un ejemplo respectivo para
cara cada uno de ellos sería Gerente
Financiero, Clientes y un sistema de
liquidación de sueldos y jornales.
En sí, las entidades
externas, muestran a las entidades con
las cuales el sistema se comunica y por
lo tanto no forman parte del sistema en
estudios; pues lo que ocurre en estas
entidades no es de interés para el
proyecto. Si así lo fuera, esto está
indicando que la frontera del sistema, es
más amplia de lo que se determinó; y
los procesos involucrados en esta
entidad, deben pasar a ser parte del
sistema en estudio.
Las entidades externas
son consideradas también como Terminadores,
pues representan el origen y el destino
de los Flujos de datos para
adentro y para fuera del sistema.
Son representadas por
medio de un cuadrado, que puede tener un
sombreado en dos de sus lados para
otorgarle un relieve (ver figura 4.2.2).
Y en el centro del cuadrado se escribe el
nombre de la entidad externa que está
siendo representada.
Cuando una entidad
externa provee datos al sistema, debe
existir un flujo de datos saliendo de la
entidad y en dirección al sistema. Y
cuando una entidad externa recibe datos
del sistema, debe existir un flujo de
datos que viene del sistema y termina en
la entidad externa.
Las entidades externa
pueden duplicarse, si fuese necesario
darle claridad al diseño y evitar largos
vectores, que representan a los flujos de
datos, o bien evitar gran cantidad de
entrecurzamientos de los mismos.
2.-Los flujos
de datos son
representados por vectores direccionados.
Ellos son las conexiones entre los
distintos elementos del sistema y los
procesos; y representan a la información
que los procesos exigen como entrada y/o
las informaciones que ellos generan como
salida. Los flujos pueden representar a
una información compuesta por un solo
elemento como por ejemplo: precio,
cantidad, Apellido; o bien pueden
representar a una información que
contiene una estructura de elementos como
por ejemplo: Orden de compra, Remito,
Factura.
3.- Los procesos
se pueden mostrar como burbujas, o como
rectángulos con sus vértices
redondeados; según sea la metodología
para modelar los procesos de Yourdon o la
de Gane & Sarson; en el diagrama
ellos representan las diversas funciones
individuales que el sistema ejecuta;
Estas funciones son las que transforman a
las entradas en salidas. El proceso es
nominado en función de la acción que
realiza sin especificar el algoritmo
utilizado para la transformación. Este
algoritmo debe ser detallado en el
diccionario de datos (ver 4.3. Diccionario de datos) o esquematizado en un
flujograma (ver 4.5. flujograma)
4.- Los archivos
de datos son mostrados por dos
líneas paralelas según la metodología
de Yourdon.; o como un rectángulo
abierto por uno de sus lados en la
metodología de Gane & Sarson. Ellos
muestran la colección de datos
que el sistema debe mantener en la
memoria en un período de tiempo. Al
terminar el diseño del sistema y la
construcción del mismo, los archivos
serán las tablas que compongan la base
de datos.
RESTRICCIONES
DEL DFD.
Como regla general, en
un DFD, loa tratamiento de errores y de
excepciones no deben ser representados; a
menos que estos sean muy relevantes para
los usuarios del sistema. El DFD debe ser
visto como una herramienta de
planeamiento del sistema, y no como una
especificación detallada del sistema. Su
finalidad es mostrar el flujo normal de
datos entre los principales elementos, y
no los detalles de implantación del
sistema.
Lo que queremos decir
es que, el diagrama de flujo de datos
ofrece una visión general y práctica de
los principales componentes funcionales
del sistema, pero no provee
detalles sobre esos componentes.
Para mostrar los detalles de qué
información es procesada y cómo es
transformada, precisamos de una
herramienta de soporte de modelización
textual y una de ellas es el diccionario
de datos (ver 4.3.el diccionario de datos).
El DFD Tampoco
provee ninguna indicación explícita de
la secuencia del procesamiento. El
procesamiento o la secuencia puede estar
implícitamente en el diagrama, pero la
representación procedimental, de cuando
inicia y finaliza cada proceso quedará
explícita en el flujograma.(ver
4.5. flujograma)
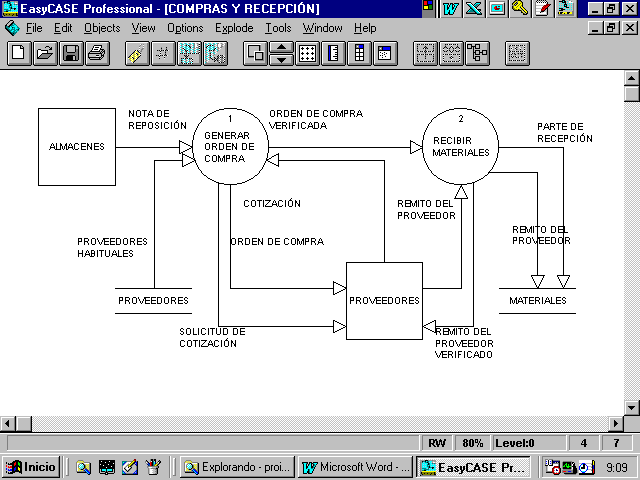
FIGURA 4.1. Diagrama de
Flujo de Datos.
RECOMENDACIONES
PARA UN DFD.
- Los DFD son más
legibles, si las entidades
externas son diseñadas sobre los
bordes del diagrama; de tal
forma, que la frontera del
sistema (o contexto) se sitúe
dentro del contorno de las
entidades externas
- Si los flujos de
datos principales van del lado
izquierdo hacia el lado derecho
del diagrama, la lectura se hará
más fácil y más rápida.
- Las duplicaciones
de símbolos deben ser mantenidas
al mínimo, pero cuidando de
mantener un número aceptable de
líneas de flujo de datos
cruzándose unas con otras.
- Inicie la
construcción del DFD por las
entidades externas, a
continuación siga con las
salidas que de ellas son
originadas, juntamente con las
entradas que irán para ellas.
Al diseñar el primer
borrador del DFD, piense en como el
sistema funciona realmente, cuál es la
entrada o proceso que inicia, y por ahí
comience el diseño.
Los primeros diseños
de un DFD siempre tendrán la finalidad
de borrador. El objetivo es la
identificación de todos las entidades
externas, procesos y archivos de datos
que formarán parte del sistema, además
de incluir los flujos de datos entre
ellos. Próximas versiones mejorarán las
definiciones y el diseño.
El orden más lógico
para diseñar un DFD es definir la
entidad externa o proceso que genera una
entrada de datos, después el proceso que
trata esa entrada, y a continuación los
archivos de datos que son utilizados para
almacenarla y para garantizar el
funcionamiento de ese proceso y por
último definir las salidas que son
generadas por dicho proceso.
El primer borrador
puede ser realizado en papel, pero los
posteriores deben ser realizados
utilizando alguna herramienta de software
automatizada (CASE) específicamente
diseñada para la modelización del
sistema de información; estas
herramientas cuentan con un diccionario
de datos, que almacenan los detalles del
modelo lógico del sistema.
4.3.EL DICCIONARIO DE DATOS
Un análisis del
ámbito de información estaría
incompleto si solo se considera el flujo
de la información. Cada flecha del
diagrama de flujo de datos representa
uno o varios elementos de información (ver 4.2. la modelización de las
funciones del sistema); cada archivo de datos
es una colección de elementos de datos
individuales; incluso puede que el
contenido de una entidad externa
requiera ser expandido antes de que su
significado pueda ser definido
explícitamente. Por lo tanto, el
analista debe disponer de algún método
para representar el contenido de cada
componente del modelo de flujo de datos.
Se ha propuesto el Diccionario
de Datos como gramática casi formal
para describir el contenido de los
objetos definidos durante el análisis
estructurado.
Esta importante
notación ha sido definida de la
siguiente marea:
El Diccionario de Datos
es un listado organizado de todos los
elementos de datos que son pertinentes
para el sistema, con definiciones
precisas y rigurosas que le permite al
usuario y al proyectista del sistema
tener una misma comprensión de las
entradas, de las salidas, de los
componentes de los repositorios, y
también de cálculos intermedios.
CONTENIDO DEL DICCIONARIO DE DATOS
El Diccionario de datos
debe contener la siguiente información:
Nombre: el
nombre principal del elemento; del flujo
de datos, del repositorio de datos o de
una entidad externa.
Alias: otros
nombres usados para la entrada, dado que
un mismo elemento puede ser conocido por
diferentes nombres.
Definición:
Exposición clara y precisa de las
características genéricas y
diferenciales del objeto.
Descripción:
Explicar las diversas partes o
circunstancias, que componen la
definición, de los objetos.
Dónde se usa/cómo
se usa: Un listado de los procesos
que usan un elemento de datos, o del
control de cómo lo usan.
Descripción del
contenido: El contenido es
representado mediante una anotación que
se describe en la siguiente tabla.
Existen muchos esquemas
de anotación usados por los analistas de
sistemas el que sigue es uno de los mas
usados
Símbolo
|
Descripción
|
=
|
Está compuesto de |
+
|
Y |
( )
|
Opcional (puede estar
presente o ausente) |
{ }
|
Interacción entre
componentes |
[ ]
|
Elección de una de las
opciones |
* *
|
Comentario |
|
|
Separa opciones de
alternativas en la construcción
[ ] |
@
|
Identificador campo
llave |
FIGURA 4.2 Diccionario
de Datos - Descripción
FIGURA 4.3 Diccionario
de Datos - Estructura
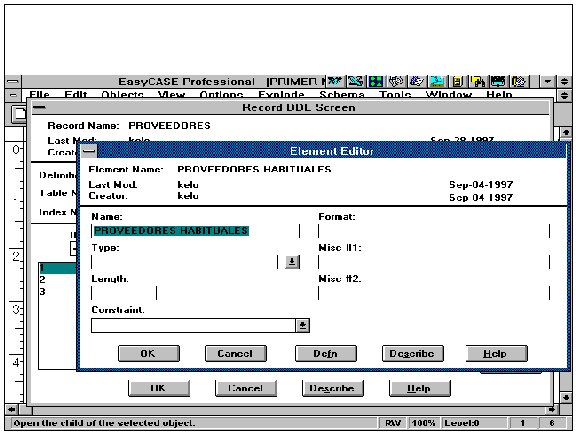
FIGURA 4.4 Diccionario
de Datos - Definición de un elemento
4.4. LA MODELIZACIÓN DE DATOS
ALMACENADOS
EL MODELO RELACIONAL DE DATOS
(RDM).
Todos los sistemas
almacenan y usan información sobre el
ambiente con el cual interactúan,
algunas veces la información es mínima,
pero en la mayoría de los sistemas, es
bastante compleja. No solamente queremos
saber, en detalle, qué información
está contenida en cada archivo de datos,
sino también que relaciones existen
entre los archivos de datos. Este
aspecto del sistema no está representado
por el diagrama de flujo de datos; pero
sí está activamente representado por el
Modelo Relacional de Datos (Relational
Data Model).
Como la anotación de
los repositorios de datos en el DFD dice
muy poco acerca de los detalles de los
datos, es necesario que a partir de
este modelo, se requiera una clara
definición de las entidades (archivos de
datos) y de sus relaciones, que conforman
parte del proyecto y que por lo tanto son
de especial interés para el usuario.
Estos datos y relaciones deben ser
almacenados a través de archivos que
posteriormente formarán la base de datos
del sistema.
Por lo tanto, el
objetivo de un RDM es el de
ilustrar la estructura de los datos del
sistema, a través de la identificación
de las entidades detectadas en el sistema
y el diseño de sus relaciones.
El RDM posee dos
importantes componentes, que son las
Entidades y las Relaciones:
- Entidades o
Tipos de objetos: Son
representadas por un cuadrado en
el RDM. Una Entidad representa a
una colección o conjunto de
objetos (cosas) del mundo real,
cuyos miembros diseñan un papel
en el sistema que se está
desarrollando. Las Entidades
pueden ser identificadas de forma
única y, ser descriptas a
través de uno o mas hechos
(Atributos). Como regla general,
tomamos que, en cada archivo de
datos definido por el DFD, se
almacenan los datos que describen
a las Entidades del sistema de
información, o sea, a cada
archivo de datos del DFD le
corresponde una Entidad al RDM.
- Relaciones:
Una relación representa un
conjunto de conexiones o
asociaciones entre las Entidades,
interligadas por vectores al
relacionamiento. Normalmente,
cada entidad que compone la base
de datos de un sistema podrá
estar relacionada con otras; por
ejemplo, un cliente podrá estar
relacionado con varias ventas,
una venta con varios productos,
un vendedor con varias ventas, y
así sucesivamente en cada uno de
los procedimientos.
Por lo tanto,
considerando que las entidades de una
base de dados están relacionadas, y que
a través de esa relación son generados
informes, como por ejemplo: todos los
productos vendidos a un cliente, es
importante definir todas las relaciones
entre las entidades y su correspondiente tipo
de relación y que veremos a
continuación.
TIPOS DE
RELACIONES
El RDM muestra los tres
tipos de relaciones posibles entre los
archivos de datos y los procesos de un
DFD: uno – a – uno; uno –
a – varios y varios – a –
varios. Pero veamos cómo son cada una de
estas relaciones:
Relación uno a
varios.
Es el tipo de relación
más común; y en este tipo de relación,
un registro de la Tabla A puede tener
muchos registros coincidentes en la Tabla
B, pero un registro de la Tabla B sólo
tiene un registro coincidente en la Tabla
A.
Relación varios a
varios.
En una relación varios
a varios, un registro de la Tabla A puede
tener muchos registros coincidentes en la
Tabla B y viceversa. Este tipo de
relación sólo es posible si se define
una tercera tabla (denominada tabla de
unión), cuya clave principal consta de
al menos dos campos; y que además, estos
campos, correspondan a las claves
externas de las Tablas A y B.
Relación uno a uno.
En una relación uno a
uno, cada registro de la Tabla A sólo
puede tener un registro coincidente en la
Tabla B y viceversa. Este tipo de
relación no es habitual, debido a que la
mayoría de la información relacionada
de esta forma estaría en una sola tabla.
Puede utilizar la relación uno a uno
para dividir una tabla con muchos campos,
para aislar parte de una tabla por
razones de seguridad o para almacenar
información que sólo se aplica a un
subconjunto de la tabla principal.
BENEFICIOS DEL
RDM
Los principales
beneficios en la utilización del RDM
son:
- Da una visión de
alto nivel de los archivos de
datos involucrados en el sistema.
- Ayuda a descubrir
los elementos o las entidades que
no fueron detectadas, al momento
de diseñar y analizar el DFD.
- Simplifica la
estructuración de los datos.
- Facilita la
definición y el análisis de las
Llaves primarias de cada archivo
de datos; como así también sus
llaves foráneas, que son
necesarias para establecer la
relación entre las entidades, y
que a través de las cuales
podrán ser procesados y
consultados los registros (ver 3.1.2.llave primaria
o identificadora).
- Facilita la
definición y el análisis del tipo
de relación existente entre
las entidades u objetos, que
conformarán la base de datos:
- uno – a
– uno, en este caso se
debe verificar que cada entidad
sea única o pude ser formada por
un conjunto de entidades de menor
nivel.
- uno – a
– varios,
- varios – a
– varios; en este caso
se debe subdividir en dos
relaciones del tipo uno – a
– varios. (ver diseño de la
relación uno a uno)
Todos estos beneficios
hacen que el RDM sea fundamental para
poder proyectar una base de datos.
Después de la
construcción del RDM, también es
necesario que sean incorporados al
Diccionario de Datos todos los datos que
fueron definidos en este modelo y que
serán almacenados en cada archivo, y que
posteriormente formarán la base de dados
del sistema proyectado.
TECNICA DE
DISEÑO DEL RDM.
Cada entidad es
representada por un rectángulo,
La relación entre las
entidades es representada por una línea
uniendo a los rectángulos a relacionar,
El tipo de relación es
representada por un par de números en la
extremidad de la línea de relación: 1 identifica una relación con un
único registro y N identifica una relación con
muchos registros y 0 identifica la relación con
ningún registro,
La descripción de la
relación debe ser hecha a lo largo de
las líneas que ligan las entidades
relacionadas.
En la Fig. 4.4.1. se
representa la relación entre dos
entidades; la entidad PERSONA y la
entidad DEPARTAMENTO. El par de números (
1 , 1 ) indica que como mínimo una ( 1 ) PERSONA trabaja en un
DEPARTAMENTO y como máximo una ( 1 ) PERSONA trabaja en un
DEPARTAMENTO. Por otro lado, el par de
números ( 0 , N ) indica que en un DEPARTAMENTO
pueden trabajar como mínimo ninguna ( 0 ) PERSONA y como máximo varias ( N ) PERSONAS.
Por lo tanto, una
PERSONA está relacionada a un
DEPARTAMENTO (1,1) y un
DEPARTAMENTO está relacionado a ninguna
o varias PERSONAS (0,N)
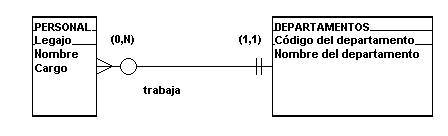
FIGURA 4.4.1. Relación
entre entidades
En el ejemplo de la
Fig. 4.4.2. cada VENTA involucra uno o
mas (1,N) productos vendidos; pero
un PRODUCTO es parte de solamente una
VENTA (1,1).
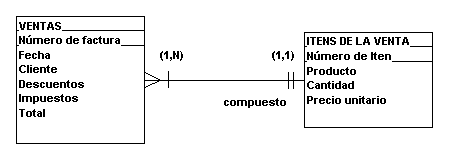
FIGURA 4.4.2.
Propiedades de las entidades y las
relaciones
En el ejemplo de la
Fig. 4.4.3. cada PROVEEDOR puede
suministrar uno o mas (1,N)
PRODUCTOS y cada PRODUCTO puede ser
provisto por uno o mas (1,N)
PROVEEDORES o viceversa pues una
relación entre dos entidades puede ser
leída en cualquiera de las dos
direcciones.
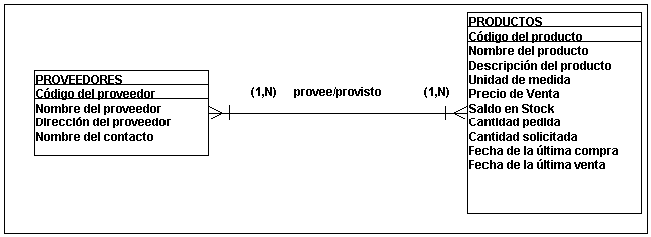
FIGURA 4.4.3.
Direccionalidad de las relaciones
Diseño de la
Relación uno a uno.
Al ser identificada una
relación uno a uno (1,1), se debe
inicialmente verificar si los dos objetos
relacionados son realmente distintos o
pueden ser unidos en un único elemento.
Si cada elemento fue
identificado con la misma llave
primaria y si ambos se complementan,
hay una fuerte razón para unir a los dos
elementos en uno solo. Por ejemplo
tenemos a las entidades PRODUCTO Y STOCK.
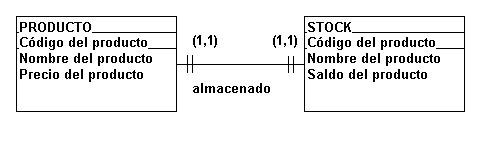
FIGURA 4.4.4. Relación
uno a uno
Como cada PRODUCTO es
almacenado en STOCK, podemos considerar
una única entidad de PRODUCTOS EN STOCK,
representada en la figura 4.4.5.
En este caso, las
entidades PRODUCTO Y STOCK no son
realmente distintas y por ese motivo,
debemos almacenarlas en un único archivo
de datos, pues el Saldo es apenas un
atributo de cada PRODUCTO (ver
4.4. Normalización).

FIGURA 4.4.5 Unión de
dos entidades relacionadas uno a uno
Si los dos elementos
fuesen realmente distintos, cada uno
debería ser identificado por una llave
primaria que lo distinga de forma
inequívoca de los demás. (ver 3.1.2 llave primaria o
identificadora).
La relación entre los
dos objetos deberá ser realizada a
través de una llave relación,
denominada llave foránea <FK> La
llave foránea deberá estar indicada en
el objeto relacionado, como se ilustra en
la figura 4.4.6. La llave foránea recibe
este nombre porque, necesariamente ella,
no es un atributo del elemento
relacionado, pero sí es la llave
primaria del elemento al cual está se
relaciona.
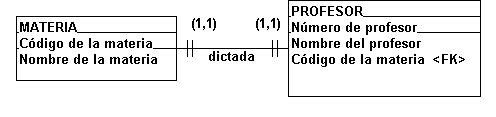
FIGURA 4.4.6.Llave
foránea <FK>
En el caso de la
relación (1,1), representada en la
figura 4.4.6, entre una MATERIA y un
PROFESOR que dicta una MATERIA; vemos al
Código de la materia como la llave
primaria de la entidad MATERIA; y la
llave primaria Número de profesor de la
entidad PROFESOR.
Si determinamos que un
PROFESOR está relacionado a una MATERIA,
precisamos pues de una llave que haga la
relación entre las dos entidades; esta
llave que como ya vimos se denomina llave
foránea y es identificada con la sigla
<FK>; y en nuestro caso quien
cumple esta función es el Código de la
materia y debe ser archivada en la
entidad que describe al PROFESOR, y
apunta a la MATERIA que él dicta, como
se ilustra en la figura 4.4.8.
Por lo tanto, en el
archivo PROFESOR, el dato "Código
de la materia" es un campo llave
foránea (FK), significando que se trata
de un dato del archivo MATERIA, pero que
precisa existir en el archivo PROFESOR
para permitir la RELACIÓN entre
ambos. Note que en esta relación, un
PROFESOR puede dictar solamente una
MATERIA, tal cual se observa en la figura
4.4.7.
Otra alternativa de
relacionar a los archivos PROFESOR y
MATERIA sería si admitimos que una
materia solamente puede ser dictada por
un profesor, esto significa que debemos
incluir la llave foránea "Número
del profesor" en el archivo MATERIA.
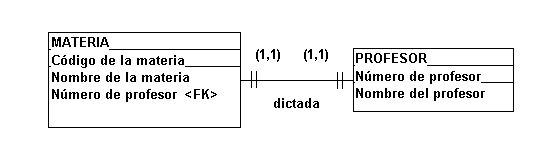
FIGURA 4.4.7 Llave
foránea
Aunque estas dos
soluciones sean posibles para la
relación entre PROFESOR y MATERIA,
ninguna de ellas está totalmente
correcta. Una mejor solución debe
permitir que un profesor pueda dictar
varias materias o que una materia pueda
ser dictada por varios profesores. O sea,
la relación entre PROFESSOR y MATERIA no
es uno a uno, sino por lo menos uno a
varios (que se trata en el punto
siguiente)
A continuación se
presentan cuatro preguntas, que sirven
como ejemplo, para presentar el análisis
que debe ser hecho al proyectarse una
relación uno a uno:
- ¿ La relación
siempre será uno a uno?
- ¿Hay alguna
posibilidad de que en el futuro
ella pase a ser uno a varios?
- ¿De que forma se
podrá adaptar ante un posible
cambio del sistema?
- ¿En qué archivo
deberá ser incluida la llave
foránea para ser utilizada como
apuntadora de la relación?
Diseño
de la Relación uno a varios.
La relación uno a
varios ocurre cuando una única instancia
de una entidad está relacionado con
otras instancias de otra entidad. Como
cada entidad posee un archivo de datos
conteniendo sus atributos, la llave
primaria de la "entidad uno"
debe ser una "llave foránea"
en el archivo que describe a la
"entidad muchos", pudiendo ser
parte de su llave primaria o no.
En el ejemplo ilustrado
por la Fig. 4.4.8., mostrando la
relación entre una MATERIA y varios
PROFESORES, el atributo "Código de
la materia" es la llave foránea de
PROFESOR.
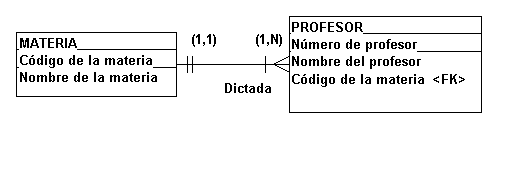
FIGURA 4.4.8.Relación
uno varios cuando una materia es dictada
por uno o varios profesores
En este caso, una
materia puede ser dictada por uno o
varios profesores (1,N), pero un profesor
solamente puede dictar una única materia
(1,1).
En el ejemplo ilustrado
por la Fig. 4.4.9., muestra la relación
entre un PROFESOR y varias MATERIAS, el
atributo "Número del profesor"
es la llave foránea de MATERIA.
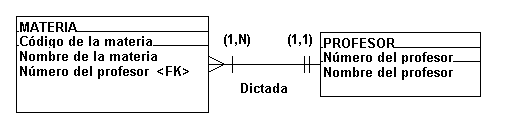
FIGURA 4.4.9. Relación
uno a varios, una materia es dictada
únicamente por un profesor.
En este caso un
profesor puede dictar una o varias
materias (1,N) pero una materia puede ser
dictada solamente por un profesor (1,1).
Diseño
de la Relación varios a varios.
Si analizamos los
ejemplos anteriores, percibimos que la
relación más correcta entre PROFESOR Y
MATERIA no es ni uno a uno ni tampoco uno
a varios, pero sí lo es varios a varios,
o sea, un profesor puede dictar muchas
materias y una materia puede ser dictada
por muchos profesores.
Una relación (N,N)
siempre debe ser resuelta por dos
relaciones (1,N), pues no es posible que
tanto PROFESOR como MATERIA reciban
llaves foráneas. En este caso,
únicamente las llaves primarias de ambos
objetos relacionados (N,N) deberán ser
identificadas y, a continuación, un
"objeto de intersección"
deberá ser creado. La llave primaria del
objeto de intersección será la
combinación o concatenación de las
llaves primarias de los dos objetos de
origen.
En el ejemplo ilustrado
por la figura 4.4.10, en que un PROFESOR
dicta varias materias(1,N) y una MATERIA
puede ser dictada por varios
profesores(1,N). La única línea de
relación (N,N) puede ser considerada
como una combinación de dos relaciones
(1,N), ambas con un objeto de
intersección.
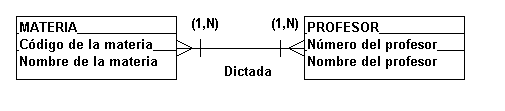
FIGURA 4.4.10 Relación
varios a varios
Para determinar los
datos que deberán estar contenidos en
los objetos de intersección a ser
creados debemos analizar la relación
(N,N) entre MATERIA Y PROFESOR haciendo
las siguientes preguntas.
¿Cuál debe ser el
objeto que posea una llave primaria que
corresponda a la concatenación de un
determinado "Código de la
materia" y de un determinado
"Número de profesor"?
¿Qué datos o
atributos dependen exclusivamente de esta
combinación?
¿Qué datos pueden ser
obtenidos si sabemos que estamos tratando
con una determinada MATERIA dictada por
un determinado PROFESOR?.
Al tratar de responder
estas preguntas verificamos que
diferentes materias pueden ser dictadas
por diferentes profesores en diferentes
horarios y aulas y, diferentes profesores
dictan diferentes materias en
determinadas aulas y en determinados
horarios.
Por lo tanto; como una
determinada materia puede ser dictada por
diferentes profesores en diferentes aulas
y en diferentes horarios, podemos crear
un objeto de intersección denominado
COMISIÓN. De esta forma, un determinado
profesor podrá dictar varias materias,
cada una en su respectiva aula y horario;
así como cada materia podrá ser dictada
por varios profesores, y para cada
profesor habrá una determinada aula y
horario.
La figura 4.4.11.
ilustra la relación (N,N) entre MATERIA
Y PROFESOR resuelta por una relación
(1,N) entre MATERIA Y COMISIÓN y una
relación (1,N) entre PROFESOR Y
COMISIÓN.
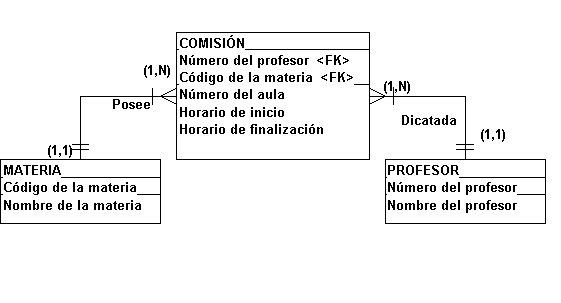
FIGURA 4.4.11 Relación
varios a varios solucionada
En este caso, la llave
primaria de COMISIÓN es compuesta por
dos llaves foráneas. O sea, para que una
COMISIÓN sea identificada es preciso
saber cual es la materia y cual es el
profesor. Como el "Código de la
materia" pertenece a la MATERIA y el
"Número de profesor" pertenece
a PROFESOR ambos son llaves foráneas en
COMISIÓN y concatenadas forman su llave
primaria, pues la identifican.
NORMALIZACIÓN.
El proceso de la
construcción del Modelo Relacional de
Datos (RDM), tiene como objetivo:
- Percibir las cosas
de significación sobre lo que se
necesita saber y mantener la
información. Esto es definir a
las entidades y diseñarlas como
un recuadro.
- Añadir las
relaciones de gestión, las
cuales se han nombrado como
asociaciones significativas entre
entidades. Esto es definir al
conjunto de conexiones que ligan
a las entidades u objetos y son
representadas por medio de
vectores.
- En cada entidad se
listan los tipos de información
que se podrían mantener o
conocer. Esto es la definición
de cada uno de los atributos por
los cuales una entidad es
conocida.
- Se determina la
forma en que cada aparición de
una entidad puede ser
identificada de forma única.
Esto es la definición de uno o
más campos identificadores o
llave.
Por lo tanto la
modelización (RDM) permite:
- Minimizar la
duplicación de datos;
- Proporcionar la
flexibilidad necesaria para
soportar requisitos funcionales y
- Que el modelo se
estructure sobre una amplia
variedad de diseños alternativos
de bases de datos.
La mayor dificultad en
este proceso es que se depende de la
buena comprensión del analista acerca de
lo que realmente es una Entidad, un
Atributo y una Relación. Para evitar tal
circunstancia es que se aplica el proceso
de NORMALIZACIÓN.
Entonces denominamos NORMALIZACIÓN
al proceso de simplificación de archivos
de datos que componen una base de datos
relacional (diseño eficaz de tablas); y
que persigue como objetivo principal
minimizar la duplicidad de información,
prevenir inconsistencias, evitar
redundancias, garantizar que no existan
pérdidas de información. En resumen son
las técnicas y algoritmos que ayudan, al
proyectista de una base de datos
relacional, a construir relaciones
normalizadas, según sea el significado y
el contenido del universo a ser modelado,
evitando, anomalías en el manejo de
estos datos
El proceso de
normalización consiste, básicamente, en
la aplicación de un conjunto de reglas
para definir adecuadamente los datos o
campos que compondrán los archivos de
datos. Esas reglas buscan:
- Minimizar
redundancias;
- Eliminar
anomalías de actualización;
- Proveer el mejor
camino de acceso a cualquier
dato;
- Asegurar
resistencia a la manutención del
modelo de datos;
- Evitar datos no
identificables a través de una
definición rigurosa de
identificadores y relaciones.
Fueron establecidos
cinco tipos de archivos normalizados,
denominados, en orden creciente de
simplicidad: primera forma normal (1FN),
segunda forma normal (2FN), tercera forma
normal (3FN), cuarta forma norma (4FN) y
quinta forma normal(5FN).
En general, las tres
primeras reglas básicas de
normalización son suficientes para
resolver la gran mayoría de casos. Es
por ello que definiremos a continuación
las tres primeras formas normales y
discutiremos la manera de simplificar los
archivos de datos hasta la tercera forma
normal. Se podría resumir a estas tres
formas normales mas utilizadas, de la
siguiente manera:
- Eliminar campos
repetitivos;
- Eliminar datos
redundantes;
- Eliminar atributos
no dependientes.
Además la 1FN, 2FN y
la 3FN son mecanismos para identificar
entidades y relaciones perdidas.
PRIMERA
FORMA NORMAL (1FN).
Asegurar que todas las
entidades son identificadas de forma
única por una combinación de atributos
y/o relaciones.
Se refiere a cualquier
archivo que posea un valor por campo; la
relación entre la llave primaria de un
archivo y cada uno de los otros campos
debe ser de uno a uno.
De una manera
práctica, debemos eliminar grupos
repetidos de datos, hasta que cada dato
tenga una llave primaria para cada
ocurrencia.
El archivo de datos
ejemplificado a continuación no está
normalizado; entre otras cosas, hay mas
de un valor o supermercado en cada campo
de Negocio.
Producto
|
Negocio
|
| Arroz |
Coto,
Disco, Carrefour, Jumbo |
| Poroto |
Coto,
Macro, Carrefour, Jumbo |
| Harina |
Coto,
Macro, Carrefour |
| Azúcar |
Tía,
Disco, Carrefour |
Como
puede percibirse, en el campo Negocio
existen varios valores de datos (grupos
repetidos). A través de este archivo
podemos obtener la información de que
existe, por ejemplo, arroz en los
supermercados Coto, Tía, Disco,
Carrefour, Jumbo. Mientras tanto ¿cómo
podríamos llegar a saber la cantidad
existente de cada uno de los productos,
en cada uno de los negocio?.
De acuerdo con la
primera forma normal este archivo debe
ser revisado para que sean eliminados los
grupos repetidos, o sea, en el campo
Negocio debe existir el nombre de apenas
un supermercado. Esto implicará, la
creación de un número mayor de filas o
registros en el archivo. Pues deberá
haber una fila para cada producto en cada
negocio. A partir de esto, podremos
fácilmente registrar la cantidad
existente de cada producto en cada
negocio.
Después de la
aplicación de la primera regla de
normalización, el archivo de datos de
los productos en Stock asume la siguiente
estructura de datos:
Producto
|
Negocio
|
Teléfono
|
Cantidad
|
Precio
|
Total
|
| ARROZ |
Coto |
670-1158 |
200 |
10 |
2000 |
| ARROZ |
Disco |
923-3951 |
500 |
9 |
4500 |
| ARROZ |
Carrefour |
921-4802 |
700 |
11 |
7700 |
| ARROZ |
Jumbo |
342-6400 |
1000 |
8 |
8000 |
| POROTO |
Coto |
670-1158 |
300 |
13 |
3900 |
| POROTO |
Macro |
923-4377 |
500 |
12 |
6000 |
| POROTO |
Carrefour |
921-4802 |
200 |
14 |
2800 |
| POROTO |
Jumbo |
342-6400 |
400 |
8 |
3200 |
| HARINA |
Coto |
670-1158 |
400 |
8 |
3200 |
| HARINA |
Macro |
923-4377 |
600 |
9 |
5400 |
| HARINA |
Carrefour |
921-4802 |
100 |
7 |
700 |
| AZUCAR |
Disco |
923-3951 |
1100 |
4 |
4400 |
| AZUCAR |
Carrefour |
921-4802 |
900 |
5 |
4500 |
| AZUCAR |
Tía |
449-7448 |
1200 |
3 |
3600 |
SEGUNDA
FORMA NORMAL (2FN).
Eliminar atributos que
dependen solamente de una parte del
identificador único
Si una entidad tiene un
identificador único compuesto de más de
un atributo y/o relación, y si otro
atributo depende sólo de una de las
partes de este identificador compuesto,
entonces el atributo, y la parte del
identificador del que depende, deberán
formar la base de una nueva entidad. La
entidad nueva, se identifica por la parte
emigrada del identificador único de la
entidad original, y tiene una relación
de uno a varios unida con la entidad
original.
Para testear si un
archivo de datos está en la segunda
forma normal debemos hacer inicialmente
las siguientes preguntas:
- ¿Cuál es el
campo o conjunto de campos que
constituye la llave primaria del
archivo?
Si la llave
primaria fuese concatenada, esto
es, formada por mas de un campo,
preguntamos también:
- ¿Hay algún campo
no-llave que dependa de apenas,
de una parte de la llave
primaria?
En el archivo del
ejemplo anterior, el producto,
por sí solo no es suficiente
para identificar inequívocamente
un determinado registro, pues
varios registros poseen el mismo
producto. Para obtener una llave
primaria exclusiva debemos
concatenar producto con negocio,
pues no hay ninguna llave
"Producto + Negocio"
duplicado. En este caso, como la
llave es concatenada, debemos
además hacer la segunda pregunta
para cada campo no-llave:
- ¿La cantidad
depende apenas de una parte de la
llave?
La respuesta es
no; pues es preciso conocer tanto
el producto como el negocio para
obtener la Cantidad.
- ¿El Precio
depende apenas de una parte de la
llave?
La respuesta es
también no; pues es Preciso
conocer tanto el Producto como el
Negocio para obtener el Precio.
- ¿El Teléfono
depende apenas de una parte de la
llave?
En este caso la
respuesta es sí; pues si usted
conoce el Negocio también podrá
saber cual es su Teléfono,
independientemente del Producto;
por lo tanto, el archivo
ejemplificado anteriormente no
está en la segunda forma normal,
pues él no pasó por el test.
Cuando un archivo de
datos no está en la segunda forma
normal, la base de datos no estará
correcta por las siguientes razones:
- El archivo de
datos ocupará mas espacio en el
disco del que será necesario,
pues el número de Teléfonos se
repite para cada Producto
almacenado en el mismo archivo;
- Si un negocio
cambia el número de Teléfono,
todos los registros de Productos
para aquel Negocio deberá tener
el campo Teléfono modificado;
- Si ocurre algún
problema con el proceso de
actualización de datos, un mismo
Negocio podrá aparecer con
números de Teléfonos
diferentes, dependiendo de cual
registro sea por el que se
accede, o sea, la integridad de
la base de datos estará perdida;
- Cuando un negocio
posee un único Producto y su
registro fuese eliminado (por
inexistencia en stock), también
será eliminado el Teléfono del
Negocio, pues podrá no existir
otro lugar en la base de datos
que lo almacene.
Para evitar estos
problemas, el archivo anterior deberá
ser dividido en dos, como se ilustra a
continuación:
Producto
|
Negocio
|
Cantidad
|
Precio
|
Total
|
| ARROZ |
Coto |
200 |
10 |
2000 |
| ARROZ |
Disco |
500 |
9 |
4500 |
| ARROZ |
Carrefour |
700 |
11 |
7700 |
| ARROZ |
Jumbo |
1000 |
8 |
8000 |
| POROTO |
Coto |
300 |
13 |
3900 |
| POROTO |
Macro |
500 |
12 |
6000 |
| POROTO |
Carrefour |
200 |
14 |
2800 |
| POROTO |
Jumbo |
400 |
8 |
3200 |
| HARINA |
Coto |
400 |
8 |
3200 |
| HARINA |
Macro |
600 |
9 |
5400 |
| HARINA |
Carrefour |
100 |
7 |
700 |
| AZUCAR |
Disco |
1100 |
4 |
4400 |
| AZUCAR |
Carrefour |
900 |
5 |
4500 |
| AZUCAR |
Tía |
1200 |
3 |
3600 |
Negocio
|
Dirección
|
Teléfono
|
| Coto |
Av.
Del trabajo 1176 |
670-1158 |
| Disco |
Emilio
Mitre 515 |
923-3951 |
| Carrefour |
Av.
La Plata 2222 |
921-4802 |
| Jumbo |
Av.
Cruz 4897 |
342-6400 |
| Macro |
Av.
Rivadavia 4735 |
923-4377 |
| Tía |
Av.
Rivadavia 7788 |
449-7448 |
Ahora los dos archivos
están en la segunda forma normal. El
archivo de PRODUCTOS EN STOCK está en la
segunda forma normal porque los campos
no-llave(Cantidad, Precio y Total) son
dependientes de toda llave primaria
concatenada Producto + Negocio y de nada
más.
El segundo archivo,
NEGOCIOS, también está en la segunda
forma normal porque él no posee una
llave concatenada y, por lo tanto, una
columna no-llave como Dirección o
Teléfono naturalmente será dependiente
del único campo llave, que es Negocio.
Analizando desde otra
perspectiva, es fácil percibir que el
archivo anterior, a pesar de estar en la
primera forma normal, contiene datos que
describen dos cosas distintas y que son
por un lado PRODUCTOS y por el otro
NEGOCIOS.
Como regla general es
importante, que un archivo de datos en
una base de datos debe almacenar datos
que describan apenas una entidad o
evento. Por lo tanto, un archivo de datos
para estar en la segunda forma normal
debe contener datos apenas sobre un
único objeto de información o una
única clase de objetos. En nuestro
ejemplo, el primer archivo ahora contiene
apenas datos sobre productos en stock y
el segundo sobre negocios.
TERCERA
FORMA NORMAL (3FN).
Eliminar los atributos
dependientes de atributos que no son
parte del identificador único.
Un archivo en la
segunda forma normal también estará en
la tercera forma normal si un campo
no-llave depende de otro campo no-llave.
Para verificar si un
archivo en la segunda forma normal
también está en la tercera forma normal
debemos preguntar: ¿Algún campo
no-llave es dependiente de cualquier otro
campo no-llave?
El archivo de los
PRODUCTOS EN STOCK posee tres campos (o
columnas) no-llave: Cantidad, Precio y
Total. Si sabemos la Cantidad y el
Precio, sabremos el Total. Por lo tanto,
el campo "Total" es dependiente
de dos campos no-llave, pues puede ser
obtenido a partir de la Cantidad
multiplicada por el Precio.
Concluimos entonces,
que el archivo de PRODUCTOS EN STOCK no
está en la tercera forma normal.
Si el campo
"Total" fuese eliminado, el
archivo de PRODUCTOS EN STOCK pasa a
estar en la tercera forma normal,
ocupando menos espacio en el disco, y sin
pérdida de información.
Producto
|
Negocio
|
Cantidad
|
Precio
|
| ARROZ |
Coto |
200 |
10 |
| ARROZ |
Disco |
500 |
9 |
| ARROZ |
Carrefour |
700 |
11 |
| ARROZ |
Jumbo |
1000 |
8 |
| POROTO |
Coto |
300 |
13 |
| POROTO |
Macro |
500 |
12 |
| POROTO |
Carrefour |
200 |
14 |
| POROTO |
Jumbo |
400 |
8 |
| HARINA |
Coto |
400 |
8 |
| HARINA |
Macro |
600 |
9 |
| HARINA |
Carrefour |
100 |
7 |
| AZUCAR |
Disco |
1100 |
4 |
| AZUCAR |
Carrefour |
900 |
5 |
| AZUCAR |
Tía |
1200 |
3 |
4.5.FLUJOGRAMAS
Como se señaló
anteriormente, el DFD es una herramienta
muy adecuada para modelizar una red de
procesos comunicantes asincrónicos.
Es por eso que precisamos de otra
herramienta para representar la lógica
y la secuencia de un procedimiento.
El flujograma es la
representación gráfica que muestra: el
comienzo y el fin de un proceso de
tratamiento de datos, y las operaciones
de decisiones necesarias para cumplirlo,
en el orden secuencial correspondiente.
No hay duda de que de
las herramientas tales como los
flujogramas, son una excelente forma
gráfica de describir fácilmente los
detalles procedimentales.
El flujograma es la
representación gráfica más ampliamente
usada para el diseño procedimental.
Desgraciadamente, es también el método
del que más se ha abusado.
Un flujograma es un
gráfico muy sencillo. Las tres
construcciones de la programación
estructurada se representan como en la
figura 5.5. La secuencia se representa
como dos cuadros de procesamiento
conectados por una línea de control. La
condición, también denominada
IF-THEM-ELSE (si- entonces - sino), se
dibujo como un rombo de decisión que, si
es verdad, hace que se realice el
procesamiento de la parte them y, si es
falso, pasa al procesamiento e la parte
else.
Los flujogramas son
usados principalmente para la
documentación física o las interfaces
del hardware dentro de un sistema.
Un flujograma contiene
dos tipos e elementos: Los bloques
y las líneas.
- Los bloques,Los
bloques pueden representar acción
o decisión.
Un bloque de
acción representa una actividad:
efectuar una operación aritmética
entre dos números, convertir un
valor en cero, etc. Su descripción
implica siempre aplicar un verbo
(hacer algo): sumar, transferir,
borrar, etc.
Un bloque de
decisión: es una forma de
expresar una consulta acerca del
cumplimiento o no de una determinada
condición o alternativa. Según sea
la respuesta que se dé a dicha
consulta (verdadero o falso) se
seguirán diferentes caminos.
- Las líneas
de dirección o flechas que
comunica los bloques y determinan
el orden secuencial en que deben
ser considerados.
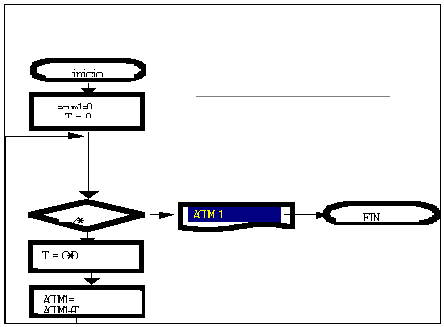
FIGURA 5.5 FLUJOGRAMA
4.6. TABLAS DE DECISIÓN
Es una forma particular
de matriz mediante la cual se representan
las acciones a tomar cuando se dan
determinadas condiciones (variables
relevantes).
Es una técnica de
aplicación en el análisis y diseño de
sistema y procedimientos: presenta un
modelo lógico de alternativas o conjunto
de alternativas de forma completa y
fácil de captar y visualizar.
En su documentación de
los sistemas brinda la ventaja de evitar
descripciones literarias de compleja
compresión. Y también como un medio de
comunicación e instrumento de
programación elimina todas las
ambigüedades o falta de precisión que
pueden surgir de las descripciones
literarias facilitando al programador la
conversión de las condiciones y
decisiones a instrucciones aplicables a
un computador.
Si hubiera N variables
con valores binarios (verdadero / falso),
entonces, habrá 2 N reglas
distintas; si hubiera 3 condiciones
habrá 8 normas.
Las tablas decisión
están divididas en cuatro cuadrantes que
conforman el siguiente esquema:
| |
REGLAS |
| DESCRIPCIÓN DE
CONDICIONES |
VALORES DE
CONDICIONES |
| DESCRIPCIÓN DE
ACCIONES |
VALORES DE ACCIONES |
Una metodología para
la creación de las tablas es la
siguiente
1 Definir e interpretar
el problema (cuidado con las obviedades);
2 Poner por escrito en
lenguaje narrativo el planteo del
problema a fin de su corroboración
3 Distinguir y separar
las condiciones de las acciones y
agruparlas respectivamente
4 Crear la tabla de
decisiones vacía, relacionando todas las
condiciones y acciones en la columna
izquierda y enumerando las combinaciones
de condiciones en lo alto de la tabla
(reglas)
5 Registrar los valores
de las condiciones y de las acciones.
6 Analizar los
resultados obtenidos (detección de
omisiones redundancias contradicciones o
ambigüedades)
7 Discutir los
resultados con los usuarios
4.7. MODULOS DE UN SISTEMA
Un DFD precisa ser
subdividido en diferentes partes, que
llamaremos módulos, conteniendo cada una
de ellos procedimientos manuales y/o
automatizadas, a fin de que el sistema
pueda ser desarrollado y ejecutado en
unidades menores, más fáciles de ser
implementadas controladas y manejadas.
Estos módulos pueden ser: un programa,
un procedimiento manual o automatizado,
una relación de operaciones o comandos,
o una combinación de estas tres.
Un módulo siempre
será invocado como una unidad, y
generalmente será desde una opción del
menú; y constituye una operación o un
procedimiento completo que el sistema
debe ejecutar.
Lo normal es que los
módulos estén relacionados con las
entradas y salida de los datos,
actualización de archivos, procedimiento
de cálculo y otras operaciones
específicas que el sistema deba
efectuar. Como ejemplo de módulos
presentamos los siguientes:
- Confección de una
NOTA DE PEDIDO
- Modificación del
los datos del CLIENTE
- Dar de baja a un
PROVEEDOR
- Grabar el Archivo
HISTÓRICO DE VENAS.
- Cálculo del
SALARIO.
- Grabar una copia
de seguridad de los archivos.
Como la división de un
sistema en módulos, se debe realizar en
función de las relaciones existentes
entre los procedimientos y su contexto;
La misma, debe tener su origen en los
procesos del DFD, y en las entidades y
sus relaciones definidas en el RDM.
Si fuese decidido que
determinado proceso tendrá apoyo
automatizado, se debe analizar la
posibilidad y la conveniencia de su
implementación por software.
Una regla práctica :
Un proceso es candidato
a ser totalmente informatizado, si todo
flujo de datos que en él entra o sale,
se encuentra en uno de estos tres casos.
1) se conecta a un
repositorio o proceso ya definido para
ser implementado por software,
2) tiene su origen en
una entidad externa y puede ser
transferido directamente par
procesamiento por software sin ningún
procesamiento adicional no informatizado
de sus datos
3) tiene como destino
una entidad externa y puede ser a él
enviado directamente de la salida de
software, sin ningún procesamiento
adicional informatizado de sus datos.
En caso de no ser
posible implementar el proceso totalmente
por software, el debe ser explotado y
revalidado continuamente, hasta que sean
completamente separados los procesos
manuales de los procesos a ser
implementados por software.
Por último, luego de
la definición de los módulos, se debe
asignar un nombre a cada módulo (que se
corresponda con el proceso definido en el
DFD) y diseñar la relación entre los
módulos.
EL
ÁRBOL DE UN SISTEMA
Los módulos ya
definidos, guardan una relación
jerárquica entre sí, o sea, existen
niveles de procesos y operaciones que
serán desempañados por el sistema,
desde los mas amplios hasta los mas
específicos. Y ésta jerarquía de
módulos es la que da origen al árbol
del sistema.
El árbol de sistema es
un organigrama, que identifica a cada uno
de los módulos y la jerarquía existente
entre ellos. Una de las funciones
principales del árbol es la de
determinar la estructura de los menús de
operaciones del sistema, pues cada
módulo, según su nivel, dará acceso o
ejecutará una determinada operación.
ESPECIFICACIÓN DE LOS MÓDULOS DEL
SISTEMA
Habiendo ya definido
los principales módulos y también
elaborado el árbol del sistema y como
cada uno de ellos está relacionado con
el DFD y con el MRD, el desarrollo y
prueba de los mismos debe ser
planificado.
Normalmente, se debe
producir y revisar una especificación
escrita para cada módulo. Esta
especificación, debe contener toda la
información necesaria para que se pueda
producir los códigos o programas
necesarios para cada uno de los módulos.
La especificación de
los módulos se realizará hasta el punto
en que se tenga un modelo claro de los
formatos de entradas y de salidas de
datos; pues la lógica del sistema, los
archivos a ser accedidos ya fueron
definidos en el DFD y el MRD.
Si los formularios e
informes del sistema fuesen generados por
un generador automático (Asistente
automático), quien programe debe saber
qué campos o datos aparecerán en cada
formulario e informe, y además podrá
utilizar el mismo generador de
formularios para definir la posición
exacta de cada campo.
|