Manual de análisis de patentes
Manual de análisis de patentes
Paul Oldham
El manual de análisis de patentes de la OMPI Paul Oldham 2019-01-16 Nota para los lectores Este es el borrador de trabajo del próximo Manual de análisis de patentes de la OMPI. El Manual se está escribiendo en abierto y actualmente está incompleto. Se añadirán nuevos capítulos a medida que estén disponibles. Si desea corregir o comentar las entradas en el Manual, presente un problema en Github aquí . Alternativamente, por favor envíe un correo electrónico poldham at mac dot como irene dot kitsara at wipo dot int. Los comentarios, correcciones y sugerencias de mejora son muy bienvenidos para garantizar que el Manual sea un recurso útil para la comunidad en general.
.
Capítulo 1 Introducción
El análisis de patentes es un campo en crecimiento que abarca el análisis de datos de patentes, el análisis de la literatura científica, la limpieza de datos, la minería de textos, el aprendizaje automático, el mapeo geográfico y la visualización de datos. El Manual de WIPO Patent Analytics proporciona una introducción a los métodos y herramientas avanzados para el análisis de patentes. El Manual complementa el Manual de la OMPI sobre análisis de patentes de código abierto, que proporciona una introducción a las herramientas y los métodos de análisis de patentes.
El Manual se centra en métodos y enfoques más avanzados que utilizan herramientas y bases de datos comerciales y gratuitas. Los campos de búsqueda de patentes, estadísticas de patentes y análisis de patentes se han transformado en los últimos años por la creciente disponibilidad de bases de datos y software gratuitos y comerciales para minería de datos, visualización de datos y mapeo geográfico. La creciente disponibilidad de una amplia gama de servicios web o interfaces de programación de aplicaciones para acceder a datos de patentes, la literatura científica y los servicios de computación en la nube para el aprendizaje automático o la geocodificación significa que hoy en día un analista de patentes tiene acceso a una gama de herramientas sin precedentes y rentable para Facilitar su trabajo.
El Capítulo 2 se centra en la investigación de la literatura científica como base para la investigación y el análisis de patentes en profundidad. Este capítulo comienza destacando la creciente accesibilidad de las publicaciones científicas y los datos que surgen de un énfasis creciente en la publicación de acceso abierto. Luego, el capítulo se centra en el papel de las búsquedas exploratorias de la literatura científica en la definición de estrategias de búsqueda de palabras clave. Luego, el capítulo explora los principales problemas que surgen cuando se trabaja con la literatura científica y cómo pueden abordarse. El capítulo concluye considerando estrategias para unir la literatura científica y la literatura de patentes.
El Capítulo 3 aborda los métodos para contar datos de patentes como base para crear estadísticas descriptivas de patentes y modelos estadísticos. Las metodologías para el recuento de patentes han recibido muy poca atención fuera de la literatura altamente especializada y este capítulo pretende ofrecer una introducción paso a paso de los problemas relacionados con el desarrollo de estadísticas descriptivas de patentes. El capítulo concluye ilustrando cómo se pueden identificar las tendencias en la demanda de derechos de patente en varios países.
El Capítulo 4 se enfoca en la Base de Datos Estadísticos de Patentes de la OEP como herramienta utilizada por muchas oficinas de patentes e investigadores como el estándar internacional para el desarrollo de estadísticas e indicadores de patentes. En común con otras bases de datos, PATSTAT requiere el uso del lenguaje SQL para generar consultas o interfaces como IISC PATSTAT que facilitan el acceso a PATSTAT.
El Capítulo 5 aborda el uso de otros campos de datos de patentes, como los nombres de solicitantes e inventores, códigos de clasificación y datos de citas en el desarrollo del análisis de innovación e indicadores de inteligencia empresarial.
El Capítulo 6 proporciona una introducción a la minería de texto como una herramienta poderosa en la caja de herramientas de analistas de patentes. Sobre la base de la discusión en el Capítulo 1, el capítulo recorre los aspectos básicos de la minería de textos con datos de patentes y concluye con un énfasis creciente en los enfoques de aprendizaje automático como el popular algoritmo Word2Vec.
Capítulo 7 geocodificación de datos de patentes para desarrollar mapas geográficos de patentes y datos relacionados a mapas geográficos. Cada vez más, es posible vincular diferentes tipos de datos en el mismo mapa utilizando los servicios de geolocalización en línea y presentar los resultados en mapas interactivos. Este capítulo analizará los principales campos de datos de patentes disponibles para el mapeo y proporcionará ilustraciones de servicios como la USPTO y el informe de paisaje de patentes marinas de la ASEAN. Se analizarán las fortalezas y debilidades de los servicios de geolocalización, como la API de Google Maps, como la naturaleza ruidosa de los nombres de patentes y campos de direcciones, los métodos para regularizar los datos de direcciones y los desafíos involucrados en la validación de los datos georreferenciados devueltos por los servicios web de geolocalización.
Capitulo 9 Se enfoca en las oportunidades presentadas por el aprendizaje automático para avanzar en el análisis de patentes. Los enfoques de aprendizaje automático o de inteligencia artificial se aplican cada vez más a la clasificación de texto y al reconocimiento de entidades nombradas y a la clasificación de imágenes. La aplicación del aprendizaje automático en el análisis de patentes se encuentra en una etapa temprana con la USPTO como pionera en la aplicación de algoritmos de aprendizaje automático para la limpieza de nombres de inventores y solicitantes, mientras que Clarivate Analytics ha aplicado recientemente el aprendizaje automático para mejorar la limpieza de nombres de solicitantes. En años futuros, es probable que veamos la aplicación del aprendizaje automático en todo el espectro de tareas de análisis de patentes. Sin embargo, puede ser muy difícil separar las exageraciones del aprendizaje automático y la inteligencia artificial de la realidad de lo que está disponible y se puede lograr ahora.
El sistema de patentes está respaldado por una gama de esquemas de clasificación que están diseñados para ayudar a los examinadores de patentes a identificar y recuperar documentos de patentes. Estos esquemas de clasificación comúnmente toman la forma de códigos alfanuméricos organizados de categorías generales a categorías específicas. El Capítulo 10 discute el uso de la Clasificación Internacional de Patentes (IPC) y la Clasificación Cooperativa de Patentes (CPC) estrechamente relacionadas en el análisis de patentes.
El Capítulo 11 discute el importante papel que desempeñan las citas de patentes en el análisis de patentes y las fortalezas y debilidades de los diferentes enfoques para el análisis de citas de patentes. El capítulo comienza con una descripción de los dos tipos de citas de patentes (citas anteriores y posteriores), las fuentes de las citas de patentes y sus impactos antes de considerar diferentes enfoques para los recuentos de citas basados en citas de documentos individuales y citas de familias de patentes.
El Capítulo 12 considera el tema emergente de las redes sociales como parte de la caja de herramientas para el análisis de patentes. Utilizando datos de Twitter como ejemplo, el capítulo considera el uso potencial de los datos de las redes sociales en áreas como la búsqueda de la técnica anterior, la comprensión de la actividad de la compañía en una tecnología, la evaluación de mercados potenciales para una invención y el debate público sobre áreas controversiales de la ciencia y la tecnología. como la inteligencia artificial.
Capítulo 2 Literatura científica.
Este capítulo examina el papel de la investigación que involucra la literatura científica y el análisis de patentes. El análisis de la literatura científica es un campo especializado por derecho propio en forma de bibliometría o scientometrics con sus propias revistas especializadas como Scientometrics y otras publicaciones (Ball 2018 ). Estos campos cubren una amplia gama de temas que involucran el análisis estadístico de literatura científica, como los indicadores de ciencia y tecnología, la exploración de los impactos de la investigación científica, las redes de investigación y la movilidad de los investigadores. Estos campos se caracterizan por una combinación de métodos cualitativos y cuantitativos y con frecuencia están orientados hacia la comprensión de las tendencias en ciencia y tecnología para informar las políticas de investigación e innovación. La relación entre la ciencia y la innovación tecnológica es un foco importante de la investigación y el análisis de vínculos de la literatura científica con la literatura de patentes. Este capítulo se enfoca en cómo el análisis de la literatura científica puede informar el análisis de patentes de las siguientes maneras principales:
- Informando estrategias de búsqueda.
- Mediante la identificación de actores activos dentro o fuera de la literatura científica como parte del análisis del paisaje.
- Identificar oportunidades potenciales para el desarrollo económico para atender las necesidades de los países en desarrollo.
Comenzaremos con una breve descripción general de las formas de acceder a la literatura científica antes de pasar a una discusión de campos de datos científicos utilizando datos de la Web of Science de Clarivate Analytics como ejemplo. Luego exploraremos cómo se puede usar la literatura científica para informar estrategias de búsqueda a través de la identificación de términos de la literatura científica para uso en búsquedas de patentes. A continuación, veremos métodos para relacionar a los actores de la literatura científica con la literatura de patentes usando datos de los países de la ASEAN como ejemplo. Finalmente, veremos cómo las comparaciones entre la literatura científica y la literatura de patentes pueden ayudar a los países en desarrollo a identificar oportunidades para que el desarrollo económico atienda sus necesidades.
2.1 Acceso a la literatura científica.
El principal medio para acceder a la literatura científica es a través de bases de datos de literatura científica y cada vez más a través de bases de datos de acceso abierto que utilizan servicios web de interfaces de programación de aplicaciones (API).
Los investigadores basados en universidades generalmente estarán familiarizados con dos de las bases de datos comerciales más grandes de la literatura científica, Web of Science / Web of Knowledge de Clarivate Analytics o Elsevier's Scopus. Las bases de datos de acceso abierto como PubMed y Crossref (que contienen metadatos de más de 96 millones de publicaciones) son cada vez más populares y están vinculadas a iniciativas como core.ac.uk que, al momento de redactar este informe, hacen públicos los textos completos de más de 113 millones de publicaciones. . Las bases de datos como Google Scholar son una fuente popular de acceso abierto de información sobre la literatura científica y el acceso a copias de textos, mientras que los sitios de redes sociales para investigadores como Research Gate proporcionan un medio para que los académicos compartan sus investigaciones y creen proyectos compartidos. Una característica importante de los desarrollos recientes en publicaciones científicas es un cambio en el énfasis hacia publicaciones de acceso abierto por parte de investigadores y agencias de financiamiento. Esto se refleja en servicios como core.ac.uk que se mencionó anteriormente y en servicios como Unpaywall, que proporciona un complemento de navegador para identificar las versiones de acceso abierto de los artículos. En la actualidad, Unpaywall contiene enlaces a más de 19 millones de publicaciones científicas. Un aspecto importante de este cambio en el énfasis hacia el acceso abierto es la integración entre servicios. Por lo tanto, Unpaywall se basa y resuelve los identificadores de artículos al contenido de Crossref, mientras que la base de datos comercial de Web of Science proporciona enlaces a Unpaywall en sus resultados para permitir la recuperación gratuita de artículos.
Como queda claro, el panorama para acceder a la literatura científica está cambiando como resultado del aumento de la base de datos habilitada para el servicio web y las herramientas de integración entre servicios. En términos prácticos, esto significa que el acceso a la literatura científica ya no depende totalmente de las bases de datos basadas en tarifas.
Es importante enfatizar que las bases de datos de publicaciones normalmente tienen fortalezas y debilidades en términos de:
- Cobertura de revistas, libros y otras publicaciones.
- Los idiomas cubiertos y la disponibilidad de las traducciones.
- La gama de campos disponibles para el análisis (autores, afiliaciones, títulos, resúmenes, etc.)
- La base de cualquier conteo estadístico (por ejemplo, conteos de artículos citados)
- La cantidad de registros que se pueden descargar.
- El formato en el que se pueden descargar los registros.
Estos problemas imponen restricciones sobre lo que se puede buscar y descargar desde bases de datos científicas. Por ejemplo, en nuestra experiencia, Web of Science permite la descarga de una gama más amplia de campos de datos que Scopus, mientras que las bases de datos de acceso abierto disfrutan de la ventaja de ser gratuitas, pero están más limitadas en términos de los campos de datos disponibles y la coherencia de Cobertura, como los resúmenes.
Cuando se busca realizar investigación bibliográfica como parte de un proyecto más amplio de análisis de patentes, es importante considerar las fortalezas y debilidades de bases de datos particulares y utilizar múltiples fuentes cuando sea necesario.
2.2 Búsqueda de bases de datos de literatura
2.2.1 Tallo
Al buscar en una base de datos de literatura, es importante como primer paso comprender los campos de búsqueda disponibles y los operadores de búsqueda (como OR y AND). Muchas bases de datos ahora ofrecen lo que se llama palabra "derivación" que buscará palabras o frases similares basadas en la raíz de los términos utilizados durante la entrada ... por ejemplo, si ingresamos la palabra "drone", una versión derivada basada en la raíz "drone "Incluiría palabras como" drones "," droned "y" droning ". En términos técnicos palabras como "drones". "Droned" y "droning" son lemas.
La búsqueda de palabras es una herramienta poderosa para ampliar el rango de búsquedas y puede extenderse al uso de sinónimos. Se pueden utilizar herramientas especializadas, como WordNet, una base de datos léxica de palabras y sinónimos en inglés, para identificar sinónimos en un término de búsqueda (Fellbaum 2015 ) . WordNet se puede utilizar en una variedad de lenguajes de programación o mediante la herramienta en línea gratuita . Los resultados de una búsqueda de WordNet para la palabra Drone se presentan a continuación:
Sustantivo
- S: (n) zángano (abeja macho sin aguijón en una colonia de abejas sociales (especialmente abejas) cuya única función es aparearse con la reina)
- S: (n) monótono, zángano, droning (una entonación invariable)
- S: (n) dawdler, drone, laggard, lagger, trailer, poke (alguien que toma más tiempo de lo necesario; alguien que se queda atrás)
- S: (n) aviones no tripulados, aeronaves sin piloto, aeronaves controladas por radio (una aeronave sin piloto que es operada por control remoto)
- S: (n) drone, drone pipe, bourdon (una tubería de la gaita que se sintoniza para producir un solo tono continuo)
Verbo
- S: (v) avión no tripulado (hacer un sonido monótono y sordo) "El armonio estaba zumbando"
- S: (v) drone, drone on (habla con una voz monótona)
El uso de una herramienta de búsqueda ayuda a revelar el rango de posibles usos de un término de búsqueda. En el caso de la palabra drone podemos ver referencias a las abejas, al sonido, a una parte de un instrumento musical y para aviones sin piloto.
El rango de usos de estos términos sugiere una necesidad de precaución. Por lo tanto, es probable que el uso del término drone en una base de datos científica arroje resultados sobre todos estos usos potenciales del drone de trabajo. Los algoritmos de activación pueden ayudar y dificultar la recuperación de información. Por ejemplo, si la derivación se activa automáticamente, la palabra "droning" se incluiría automáticamente y, por lo tanto, llenará los resultados con datos sobre el tema irrelevante del sonido para aquellos interesados en la tecnología de drones. En contraste, donde la herramienta de derivación muestra sinónimos, es posible que desee incluir aeronaves sin piloto en la búsqueda original.
En la práctica, cuando se inicia una búsqueda en una base de datos de literatura científica sobre un tema desconocido, generalmente es mejor desactivar la derivación y concentrarse en descargar un conjunto de pruebas de resultados para su revisión. El objetivo aquí es utilizar un conjunto limitado de términos para identificar otros términos potencialmente relevantes y los términos que se pueden excluir de una muestra.
Este enfoque se puede utilizar con una amplia gama de herramientas de software, incluidas herramientas simples como Excel o herramientas en línea gratuitas. El objetivo es tomar los campos disponibles, como el título, el resumen y las palabras clave del autor, y desglosarlos en sus palabras y frases constituyentes. Este es un proceso conocido como tokenización de campos de texto en palabras, frases (ngrams), oraciones y párrafos de varias longitudes y es una característica fundamental de la lingüística computacional, la minería de textos y el aprendizaje automático [refs] . Veremos con mayor detalle la minería de textos en el Capítulo 6 .
Una herramienta poderosa para trabajar con datos científicos y de patentes es VantagePoint de Search Technology Inc. VantagePoint está disponible en una edición para estudiantes y en versiones de 32 y 64 bits para Windows. VantagePoint es capaz de importar una amplia gama de diferentes fuentes de datos y automáticamente tokenizar campos de texto en palabras y frases.
La tabla 2.1 a continuación presenta los 50 mejores términos combinados en los títulos, resúmenes y palabras clave de autor de una búsqueda en Web of Science para las palabras drone o drones entre 2010 y 2017.
| archivos | condiciones | multi palabra |
|---|---|---|
| 479 | drones | 0 |
| 241 | zumbido | 0 |
| 240 | resultados | 0 |
| 181 | estudiar | 0 |
| 170 | utilizar | 0 |
| 141 | artículo | 0 |
| 126 | Derechos reservados | 1 |
| 91 | número | 0 |
| 89 | reinas | 0 |
| 88 | desarrollo | 0 |
| 87 | trabajadores | 0 |
| 86 | Apis mellifera | 1 |
| 85 | datos | 0 |
| 85 | UAV | 0 |
| 84 | uno | 0 |
| 81 | colonias | 0 |
| 69 | análisis | 0 |
| 62 | hora | 0 |
| 60 | primero | 0 |
| 56 | efectos | 0 |
Cuando inspeccionamos los resultados en la Tabla 2.1 , vemos una lista completa de palabras y frases. Muchos de estos no serán relevantes para los drones como tales, por ejemplo, las palabras artículo o estudio y los términos ruidosos comunes como "y, o, de, para" se suelen excluir como palabras de detención. En otros casos, las referencias a la palabra "reinas" o su raíz "reina" junto con "Apis mellifera" y "colonias" sugieren que tenemos muchos datos sobre las abejas en los datos. En nuestra próxima iteración de la búsqueda probablemente querríamos excluir explícitamente estos términos de la búsqueda. Sin embargo, también podemos detectar otros trabajos que podríamos incluir en nuestra búsqueda, como "UAV" para vehículos aéreos no tripulados.
En la práctica, las frases de varias palabras (ngrams) expresan conceptos (ref. Mogatov?) Y nos acercan a los términos que desearemos utilizar en una búsqueda. La tabla 2.2 clasifica los datos según las frases de varias palabras.
| archivos | condiciones | multi palabra |
|---|---|---|
| 126 | Derechos reservados | 1 |
| 86 | Apis mellifera | 1 |
| 50 | abeja | 1 |
| 49 | vehículos aéreos no tripulados | 1 |
| 44 | abejas de miel | 1 |
| 42 | Vehículos aéreos no tripulados (UAV) | 1 |
| 40 | Estados Unidos | 1 |
| 32 | teledetección | 1 |
| 29 | vehículo aéreo no tripulado (UAV) | 1 |
| 28 | vehículo aéreo no tripulado | 1 |
| 28 | Varroa destructor | 1 |
| 25 | ataques con drones | 1 |
| 24 | años recientes | 1 |
| 23 | Elsevier Ltd | 1 |
| 22 | resultados experimentales | 1 |
| 20 | guerra de drones | 1 |
| 20 | estudio actual | 1 |
| 479 | drones | 0 |
| 241 | zumbido | 0 |
| 240 | resultados | 0 |
La Tabla 2.2 revela frases irrelevantes como "abeja" y su plural "abejas" junto con Varroa destructor , un ácaro que parasatiza a las abejas. También observamos la prevalencia de vehículos aéreos no tripulados y sus plurales vinculados al término UAV y las aplicaciones de la tecnología de aviones no tripulados, como "guerra de aviones no tripulados" y "ataques con aviones no tripulados".
Por lo tanto, una revisión de los términos capturados en la investigación exploratoria inicial puede contribuir en gran medida a refinar una estrategia de búsqueda para mejorar y enfocar el recuerdo y la precisión (refs).
Nos hemos centrado aquí en los términos principales en los datos. Sin embargo, en otros casos, puede ser apropiado revisar la lista completa para identificar términos de baja frecuencia pero altamente relevantes. Este tipo de tarea se puede abordar computacionalmente, por ejemplo, creando una matriz de términos vinculados a un término específico [ejemplo, vehículo aéreo no tripulado] para capturar términos estrechamente relacionados. Como alternativa, el uso del algoritmo de frecuencia de documentos de frecuencia inversa de término (TFIDF). Este es un cálculo extremadamente popular que evalúa los términos según la importancia que tienen para el conjunto de documentos en el corpus. La idea clave detrás de la Frecuencia de Documentos Inversa proviene de Karen Spark Jones en 1972, quien propuso que: "... los términos deben ponderarse según la frecuencia de recolección, de modo que las coincidencias en términos menos frecuentes y más específicos sean de mayor valor que las coincidencias en términos frecuentes.(Jones 1972 , @ Robertson_2004) . En otras palabras, el uso de palabras de alta frecuencia TFIDF como "el" o "y" recibe ponderaciones más bajas que los términos específicos del documento como "vehículo aéreo no tripulado" que distinguen los documentos del conjunto más amplio.
El algoritmo TFIDF es extremadamente utilizado en la recuperación de información y está integrado en herramientas como VantagePoint.
En la práctica, el uso de matrices para identificar palabras y frases cercanas o TFIDF puede no ser necesario y dependerá de qué tan específico pueda ser su búsqueda de temas. Otros métodos más recientes, como Word2Vec, se considerarán con mayor detalle en el Capítulo 6
2.2.2 Usando Operadores de Búsqueda
Muchas bases de datos incluyen opciones para búsquedas basadas en operadores. Los operadores comunes son: OR, AND y NOT.
esto o que esto y que esto NO que
El operador OR es un operador abierto, por ejemplo, podríamos buscar
drone o drones o droning
Esto localizará textos que contengan cualquiera de estos términos. Si quisiéramos restringir la búsqueda a aquellos que contienen todos los términos, usaríamos AND.
drones y drones y drones
Tenga en cuenta que esta es una forma de búsqueda más restrictiva porque los documentos deben contener las tres palabras.
Por el contrario, si estuviéramos interesados en la tecnología de drones y no en otros usos de la palabra drone, como en los instrumentos musicales, NO utilizaríamos.
dron o drones no droning
Esto solo devolvería documentos donde aparecieran los términos de búsqueda drone o droning sin la palabra droning. Otra estrategia quizás más precisa sería excluir también la música.
dron O drones NO (abeja O abejas O "Apis mellifera" O "miel" O dronear O música)
Los paréntesis en la consulta de búsqueda anterior son importantes porque especifican que los documentos que contienen be o bees, etc., deben excluirse de los resultados. El uso de la búsqueda NO basada es una forma poderosa de excluir documentos irrelevantes.
Los operadores booleanos son extremadamente importantes al construir los términos de búsqueda y pueden expresarse de otras maneras si se usan bases de datos de manera programática. Por ejemplo, en R tanto | y || significa OR y & o && significa AND. En contraste, Python utiliza OR lógico, AND lógico, NO lógico. Un número creciente de bases de datos son impulsadas por Apache Lucene o Solr basado en Java. En Lucene y Solr, además de los operadores estándar, también hay "+" que especifica que un documento debe contener un término y puede contener otro término.
+ dron "vehículo aéreo no tripulado"
Para forzar a los dos a aparecer usaríamos o el AND normal.
+ avión no tripulado + "vehículo aéreo no tripulado"
Tenga en cuenta que los paréntesis en la versión anterior son importantes porque articula que uno u otro término debe excluirse de los resultados.
2.2.3 Operadores de proximidad
Los operadores de proximidad se centran en la distancia entre las palabras en un término de búsqueda, por ejemplo, el operador NEAR con Web of Science permite al usuario especificar la distancia entre las palabras, por ejemplo (drone OR drone) NEAR/10 droning, los textos que contienen la palabra drone o drone dentro de las 10 palabras de la palabra droning. Otra opción, de nuevo de Web of Science es la MISMA. Esto se usa en las búsquedas del campo de afiliación del autor para tratar dos palabras como iguales durante la búsqueda, como en la dirección field AD=(McGill Univ SAME Quebec SAME Canada). Esta búsqueda tratará la palabra Quebec y Canadá como la misma.
Los operadores de proximidad pueden proporcionar herramientas poderosas para la búsqueda de literatura científica. Sin embargo, cuando se prepara para desarrollar su búsqueda, es importante verificar la configuración predeterminada utilizada por la base de datos y si esto satisface sus necesidades. Además, es importante tener en cuenta los operadores que están disponibles y el formulario que se espera. Estos típicamente varían en las diferentes bases de datos. Por ejemplo, muchas bases de datos activan la derivación de forma predeterminada, usan AND (en lugar de OR) como el valor booleano predeterminado y pueden usar ADJ (adyacente) como operador predeterminado. Es importante verificar estos ajustes al principio para evitar resultados confusos cuando se trabaja con múltiples datos
2.2.4 Expresiones regulares
El uso de expresiones regulares se tratará con mayor detalle en la discusión de la minería de textos. Sin embargo, vale la pena señalar que las expresiones regulares comunes que puede usar en una base de datos de literatura incluyen
^comienza con *cualquier carácter comodín. Por ejemplo dron*, capturaría drones, drones, droned, droning, etc. Esto se puede usar al principio, en la mitad o al final de un término, pero se usa comúnmente al final. El comodín se debe utilizar con precaución. Por ejemplo, una búsqueda de literatura relacionada con la genómica utilizando la raíz genomy el comodín genom*capturará un número potencialmente grande de resultados para la palabra alemana común genommen(toma). $termina con. Por ejemplo, drone$se excluirían los drones y otros términos cercanos, sin embargo, capturaría los términos que contienen drones, como la palabra italiana androne (que significa entrada o entrada). Como tal, cuidado con los resultados inesperados.
Las expresiones regulares se pueden combinar en una variedad de formas. Una de las más útiles es la coincidencia exacta.
^drone$ Esto coincidirá exactamente con la palabra drone y ningún otro término.
El compromiso muy básico con expresiones regulares es una herramienta poderosa y vale la pena aprender lo básico. Un buen lugar para comenzar es el tutorial de expresiones regulares de larga data . Sin embargo, tenga en cuenta que las expresiones regulares pueden llegar a ser complejas y difíciles de entender con bastante rapidez. Una cita bien conocida sobre expresiones regulares se atribuye al ex ingeniero de Netscape Jamie Zawinski en un grupo de discusión de Usenet desde 1997.
Algunas personas, cuando se enfrentan a un problema, piensan: "Lo sé, usaré expresiones regulares". Ahora tienen dos problemas. 1
El punto que se señala aquí es que las expresiones regulares no deben ser la herramienta de primera instancia para cada problema. Las expresiones regulares pueden llegar a ser muy complejas y difíciles de entender para un lector, incluido su autor. Una vez dicho esto, una comprensión básica de las expresiones regulares es una parte muy importante de la caja de herramientas de los analistas de patentes, ya que le permite controlar con precisión lo que está buscando y analizar los resultados. La simbolización de los textos discutidos anteriormente es un ejemplo de esto que generalmente se basa en coincidencias de límites de palabras (como \\b) mientras que el reconocimiento de la entidad nombrada en los textos a menudo se basa en la identificación de términos en mayúsculas como ^[[:upper]]o^[A-Z]para identificar nombres propios (que están marcados por el uso de letras mayúsculas al comienzo de la palabra) como personas, lugares y otros nombres de entidades. La forma precisa de una expresión regular a menudo depende del lenguaje que se usa con Open Refine's GREL o Google Regular Expression Language, que proporciona una buena introducción práctica para el uso de expresiones regulares, como se explica en el Capítulo 8 del Manual de la OMPI sobre análisis de patentes de código abierto . Los lenguajes de programación como R incluyen paquetes especiales stringrque facilitan el trabajo con expresiones regulares y se han desarrollado hojas de trucos para ayudar a recordar las expresiones regulares. 2 . Sitios web como el tutorial de expresiones regulares y https://regex101.com/ Le permite probar expresiones regulares en una variedad de diferentes lenguajes de programación.
2.3 Precisión vs. Retirada
Al final de la fase de prueba con literatura científica, un resultado deseable es un conjunto de nuevos términos candidatos y términos de exclusión. Por ejemplo, un enfoque más refinado para el desarrollo de una consulta de búsqueda para la tecnología de aviones no tripulados podría tener este aspecto.
"Drone" O "drones" O "UAV" O "UAVs" O "Vehículo aéreo no tripulado" O "Vehículos aéreos no tripulados" O "Avión sin piloto" NO ("abeja" O "abejas" O "Apis mellifera" O "miel" O "droning" O "música")
El uso de las comillas en este caso está destinado a evitar que la base de datos contenga los términos individuales y el efecto es aumentar el nivel de precisión en la inclusión y exclusión de los términos. Si bien sería posible modificar esto de varias maneras utilizando los comodines o los marcadores de límites, la importancia de este tipo de enfoque es que es simple, transparente, fácil de reproducir y fácil de modificar de una manera que se puede probar.
La discusión anterior está vinculada a un cuerpo de literatura mucho más amplio sobre la distinción entre Precisión y Recall en la teoría de la información [refs] . Para una base de datos de literatura, un ejemplo de esto sería ingresar en un conjunto de términos donde la base de datos devuelve 30 páginas en drones que contienen cajas de pizza, de los cuales solo 20 son relevantes pero no devuelve los otros 40 documentos relevantes. Esa es una tasa de precisión de 20/30 = 2/3, ya que solo 2 tercios de los documentos devueltos están en el tema. En contraste, la tasa de recuperación es 20/60 o 1/3 porque la base de datos solo devolvió un tercio de los documentos relevantes reales. 3 La primera medida es sobre la precisión de los resultados y la segunda sobre la integridad de los resultados.
En la práctica, la precisión frente a la recuperación está a punto de lograr un buen equilibrio entre precisión (precisión) y recuperación (completo). Una estrategia para lidiar con esto es comenzar por favorecer la integridad tratando de capturar el universo de cosas relacionadas con un tema y luego filtrar los datos para obtener resultados más precisos para abordar el tema en cuestión.
En la siguiente sección usaremos ejemplos del panorama científico y de patentes para recursos genéticos marinos que usaron exactamente esta estrategia. El punto de partida de la investigación fue capturar todas las publicaciones científicas que contenían un autor de uno de los diez países del sudeste asiático o que contenían una referencia al país en el título, el resumen o las palabras clave de autor de una publicación. Este enfoque capturó el universo de cosas que necesitaban ser capturadas. Ese universo demostró ser 391,380 publicaciones después de filtrar algunos de los conjuntos de datos de países más grandes en categorías temáticas para reducir áreas temáticas irrelevantes. El objetivo aquí era capturar el universo de cosas que potencialmente podrían contener una especie marina o recursos genéticos. La segunda etapa de este ejercicio involucró el texto extrayendo los títulos, Resúmenes y palabras clave de autor para nombres de especies marinas. Esto redujo radicalmente el conjunto de datos a 6,659 publicaciones científicas. Como queda claro, el uso de este método puede ser costoso en términos de los requisitos de la recuperación de datos inicial, pero tiene la ventaja de capturar el universo de documentos relevantes. Sobre esa base, las especies marinas en los datos podrían ser apuntadas con precisión.
Una restricción muy importante cuando se trabaja con la literatura científica en oposición a los datos de patentes es que es muy raro que el texto completo de un artículo científico esté disponible para su búsqueda. Esto tiene un impacto importante pero no fácilmente cuantificable en la memoria porque el cuerpo principal del texto es o
Los debates en torno a la precisión y el recuerdo y los conceptos relacionados, como la relevancia, son importantes en una amplia gama de campos de recuperación de información y computación, que incluyen, por ejemplo, la clasificación de texto e imagen en los enfoques de aprendizaje automático descritos anteriormente. Como usuarios habituales de los motores de búsqueda, los analistas de patentes, al igual que otros usuarios habituales, encontrarán los resultados de las decisiones sobre cómo manejar el equilibrio entre la precisión y el recuerdo con un grado variable de éxito en la presentación de resultados útiles para el buscador. Volveremos a este tema en la discusión del aprendizaje automático.
2.4 Procesamiento de la literatura científica.
Las bases de datos de la literatura científica comúnmente devuelven una variedad de campos diferentes cuando se descargan los datos. Estos pueden variar ampliamente, pero comúnmente incluirán la mayoría de los siguientes:
- Nombre del autor
- Afiliación del autor
- Título
- Resumen
- Palabras clave del autor
- Identificador de documento (por ejemplo, doi, issn, isbn)
- Reconocimiento de fondos (cobertura limitada)
- Referencias citadas
- Recuento de citas
- Categoría del sujeto (derivado)
- Identificador del investigador (ORCID, identificación del investigador, identificación de PubMed, otra identificación)
Estos datos se extraen principalmente de la primera página de publicación o, en el caso de las referencias, del final del documento. Sin embargo, la categoría de temas se agrega comúnmente en la base de datos de publicaciones y se basa comúnmente en la clasificación de los temas de las revistas en lugar de los artículos individuales. En el momento de redactar este informe, Web of Science utilizaba 252 categorías de sujetos y revistas de grupos Scopus en 4 áreas temáticas amplias y 334 campos. 4 . Una revista puede ser clasificada en más de un área temática con algunos como Ciencia, Naturaleza y PLOS clasificados como interdisciplinarios. El uso de categorías de materias combinadas con el análisis de citas ha sido fundamental para las iniciativas en la comunidad de scientometrics para desarrollar mapas de la ciencia (Leydesdorff y Rafols 2009, @ Klavans_2009, @ Rafols_2010 y para un enfoque alternativo basado en clics web, @ Bollen_2009 ) que incluye mapas interactivos en línea como https://www.scimagojr.com/shapeofscience/ utilizando datos de Scopus con una galería de mapas en la estructura de ciencia de una variedad de fuentes disponibles a través de http://scimaps.org/ .
El procesamiento de la literatura científica sigue un patrón que es muy similar a los datos de patentes como se discutió en el Capítulo 3 . Estos pasos se pueden describir de la siguiente manera:
- Deduplique los registros utilizando identificadores de documentos (como el Identificador único ISI de Web of Science o equivalente) para asegurarse de que no se haya contabilizado ningún registro.
- Revise el conjunto de datos para el ruido y excluya el ruido según sea necesario.
- Nombres de autor limpio
- Nombres limpios de afiliación / organización
- Información de financiación limpia para centrarse en las organizaciones de financiación
- Visualizar los datos
La deduplicación de los datos es importante para evitar el conteo excesivo y se puede lograr fácilmente utilizando identificadores de documentos. Tenga en cuenta que la mejor fuente para esto a menudo son los identificadores internos utilizados por las bases de datos, ya que se garantiza que tienen una cobertura del 100% a diferencia del campo doi (normalmente limitado a artículos de revistas).
La exclusión del ruido del conjunto de datos generalmente implicará revisar los datos por categoría temática. La Tabla 2.3 a continuación muestra las categorías de temas principales en una muestra de 1400 publicaciones para el término drone o drones de Web of Science.
| Archivos | Categoría de la asignatura | mantener | revisión | excluir |
|---|---|---|---|---|
| 150 | Entomología | 0 | 0 | 1 |
| 136 | Ciencias multidisciplinares | 0 | 1 | 0 |
| 112 | Relaciones Internacionales | 1 | 0 | 0 |
| 100 | Ingeniería, Eléctrica y Electrónica. | 1 | 0 | 0 |
| 82 | Ciencias Políticas | 1 | 0 | 0 |
| 70 | Ley | 1 | 0 | 0 |
| 64 | Telecomunicaciones | 1 | 0 | 0 |
| 58 | Ecología | 0 | 1 | 0 |
| 52 | Ciencias Ambientales | 0 | 1 | 0 |
| 46 | Zoología | 0 | 0 | 1 |
| 43 | Teledetección | 1 | 0 | 0 |
| 40 | Ingeniería, Aeroespacial | 1 | 0 | 0 |
| 38 | Robótica | 1 | 0 | 0 |
| 37 | Biología | 0 | 1 | 0 |
| 36 | Informática, Sistemas de Información | 1 | 0 | 0 |
Aquí podemos ver que tenemos un número significativo de publicaciones en Entomología y Zoología que es muy probable que sean sobre abejas en lugar de tecnología de aviones no tripulados. Cuando se usa VantagePoint, es fácil crear grupos como mantener, revisar y excluir las decisiones de registro en los datos para incluirlos o excluirlos como base para refinar un conjunto de datos. La categoría de revisión es importante porque las categorías de temas de las revistas son un tanto toscas. Por ejemplo, las ciencias multidisciplinares incluirán publicaciones sobre tecnología de aviones no tripulados y sobre abejas. Los temas relacionados con la agricultura también son una categoría de revisión probable porque la tecnología de las abejas y los zánganos pueden aparecer en esta categoría, por ejemplo, para monitorear campos.
El uso de categorías de sujetos es a menudo un primer lugar para mirar con categorías de muy alta frecuencia o de baja frecuencia como buenos candidatos para el ruido. Sin embargo, un segundo paso complementario es mirar las fuentes de las publicaciones. Una muestra de estos datos para la tecnología de aviones no tripulados de Web of Science se presenta en la Tabla 2.4 .
| Archivos | Título de la fuente | mantener | revisión | excluir |
|---|---|---|---|---|
| 49 | CIENTÍFICO NUEVO | 0 | 1 | 0 |
| 40 | APIDOLOGIA | 0 | 0 | 1 |
| 26 | MÁS UNO | 0 | 1 | 0 |
| 23 | REVISTA DE INVESTIGACIÓN APICOLA | 0 | 0 | 1 |
| 20 | Sensores | 1 | 0 | 0 |
| 18 | Aeroespacial america | 1 | 0 | 0 |
| 17 | RELACIONES EXTERIORES | 1 | 0 | 0 |
| 17 | Sensor remoto | 1 | 0 | 0 |
| 15 | ASUNTOS INTERNACIONALES | 1 | 0 | 0 |
| 14 | ESPECTRO IEEE | 1 | 0 | 0 |
| 13 | REVISTA DE CIENCIA APICOLA | 0 | 0 | 1 |
| 12 | ETICA Y ASUNTOS INTERNACIONALES | 1 | 0 | 0 |
| 12 | REVISTA DE SISTEMAS INTELIGENTES Y ROBÓTICOS | 1 | 0 | 0 |
| 12 | REVISTA DE LIBROS DE NUEVA YORK | 1 | 0 | 0 |
| 11 | INSECTOS SOCIAUX | 0 | 0 | 1 |
| 11 | NACIÓN | 1 | 0 | 0 |
| 11 | Informes cientificos | 0 | 1 | 0 |
| 10 | NOTICIAS QUÍMICAS E INGENIERÍA | 1 | 0 | 0 |
| 10 | LEY DE COMPUTO Y REVISIÓN DE SEGURIDAD | 1 | 0 | 0 |
| 10 | REVISTA DE ENTOMOLOGIA ECONOMICA | 0 | 0 | 1 |
| 10 | REVISTA DE BIOLOGIA EXPERIMENTAL | 0 | 0 | 1 |
| 9 | CIENCIA | 0 | 1 | 0 |
| 9 | DIALOGO DE SEGURIDAD | 1 | 0 | 0 |
| 8 | BOLETIN DE LOS CIENTÍFICOS ATÓMICOS | 1 | 0 | 0 |
| 8 | REVISTA INTERNACIONAL DE SENSACIONES REMOTAS | 1 | 0 | 0 |
En este caso, podemos ver que las publicaciones como Apidologie pueden excluirse fácilmente, ya que las revistas como PLOS ONE que se publican en diversos campos requieren una revisión. También podemos ver que una serie de temas de ciencias sociales y humanidades están entrando en escena y, dependiendo de nuestro propósito, es posible que deseamos centrar las publicaciones en las relacionadas con la teledetección, la ingeniería y temas relacionados.
Como parte de este proceso de revisión, es importante no adivinar el área de tecnología. Por ejemplo, no debemos asumir que todo lo relacionado con la biología debe ser excluido. La biomimetica es, por ejemplo, un área importante de inspiración en algunas áreas de la tecnología de drones (como el comportamiento de enjambre), mientras que algunas publicaciones que se refieren a drones y biología se refieren al uso de la tecnología de drones en la biología contra la caza furtiva y la conservación. Es precisamente por la falta de previsibilidad.De las áreas nuevas y emergentes de la tecnología, un enfoque que se concentra inicialmente en la recuperación y luego en la precisión es a menudo la ruta más exitosa para el análisis preciso. La alternativa es que los analistas impongan una definición de un área de nueva tecnología en el campo de la investigación y, por lo tanto, excluyan potencialmente las características importantes del campo de la tecnología y los debates en torno a esos campos (como los ataques con drones militares).
El resultado de este proceso de revisión es que cada registro cae en una categoría de mantener o excluir y se genera un conjunto de datos más pequeño que contiene los datos que el analista desea conservar. En esta etapa, puede comenzar el cuerpo principal de limpieza de datos que se centra en las organizaciones de autores (en la afiliación del autor) y los nombres de los autores junto con el texto en el reconocimiento de fondos.
El procedimiento básico para la limpieza de nombres se ha descrito en el Capítulo 8 del Manual de la OMPI sobre análisis de patentes de código abierto.utilizando la herramienta de software gratuita Open Refine. Sin embargo, la precisión en la limpieza de nombres se logra mejor utilizando múltiples criterios de coincidencia para abordar los casos en que un autor comparte un nombre con otro autor pero es una persona distinta. VantagePoint proporciona un medio para lograr esto al vincular un algoritmo de limpieza de nombres de lógica difusa que agrupa los nombres en función de las puntuaciones de similitud con una configuración que permite que otro campo se use para hacer coincidir los datos. Esa es una búsqueda de John Smith que se ejecuta sin criterios de coincidencia agrupará diferentes John Smith. Una limpieza que se lleva a cabo agrupando a John Smiths mediante la afiliación del autor distinguirá entre John Smiths que trabaja en, por ejemplo, la Universidad de California o John Smiths, que trabaja en la London University. Como este ejemplo también sugiere que la limpieza de nombres es a menudo un proceso de varios pasos, porque en realidad muchos John Smith pueden trabajar en la Universidad de California. En ese caso, un segundo paso podría ser el uso de coautores compartidos o categorías temáticas como base para la toma de decisiones utilizando elkeep, review, excludemétodo descrito anteriormente. Luego se aplica el mismo enfoque a la organización solicitante, donde se requiere atención especial a las organizaciones que comparten nombres similares pero que son entidades distintas. Así, la Universidad de Washington y la Universidad de Washington son entidades distintas. Al limpiar nombres de organizaciones, tenga en cuenta que deben tomarse decisiones sobre cómo dirigirse a organizaciones regionales e internacionales y proporcionar notas en el informe o publicación resultante sobre la toma de decisiones para informar al lector.
Al considerar el proceso de limpieza para los nombres de autores descritos anteriormente, no es a menudo más fácil comenzar por limpiar los nombres de afiliación del autor y luego limpiar los nombres de los autores utilizando los nombres de las organizaciones limpiadas como criterios de coincidencia.
Un desarrollo importante en los últimos años ha sido el uso creciente de identificadores de autor en los registros de publicación. Existe una serie de sistemas de identificación de autores, como el ID de investigador de Web of Science o Scopus ID y PubMed ID, pero el más importante de estos es ORCID, que es un sistema de identificación de investigadores de acceso abierto sin fines de lucro. Cuando hay un identificador de investigador disponible, estos identificadores se pueden usar para agrupar variaciones de nombres con un grado de certeza de que son la misma persona o que las personas con el mismo nombre con ID de ORCID distintas serán de hecho personas distintas. En un nivel más alto de detalle, los perfiles públicos de ID de ORCID se pueden consultar en línea para ayudar a evaluar si un investigador que figura en una institución se ha mudado a otra. Los casos de movimiento de autores con frecuencia implicarán una investigación que trabaje en la misma área de investigación pero que incluya más de una afiliación. Los identificadores ORCID ayudan a resolver estos casos.
Los datos de financiamiento son una característica relativamente nueva en las bases de datos de publicación y la presencia de estos datos, que comúnmente aparece en el campo Agradecimientos, puede ser espectacularmente desordenada. Por ejemplo:
La red COLOSS (Prevención de las PÉRDIDAS DE LA LUCHA DE LAS ABEJAS MELICULARES) tiene como objetivo explicar y prevenir las pérdidas masivas de colonias de abejas. Fue financiado a través del COST Action FA0803. COST (Cooperación Europea en Ciencia y Tecnología) es un medio único para que los investigadores europeos desarrollen conjuntamente sus propias ideas y nuevas iniciativas en todas las disciplinas científicas a través de redes transeuropeas de actividades de investigación financiadas a nivel nacional. Basado en un marco intergubernamental paneuropeo para la cooperación en ciencia y tecnología, COST ha contribuido desde su creación hace más de 40 años a cerrar la brecha entre la ciencia, los responsables políticos y la sociedad en toda Europa y más allá. COST cuenta con el apoyo del Séptimo Programa Marco de la UE para actividades de investigación, desarrollo tecnológico y demostración (Diario Oficial L 412, 30 de diciembre de 2006). La European Science Foundation como agente de implementación de COST proporciona la Oficina de COST a través de un Acuerdo de Subvención de la CE. El Consejo de la Unión Europea proporciona la Secretaría COST. La red COLOSS ahora es compatible con la Fundación Ricola - Naturaleza y Cultura.
Las bases de datos de literatura intentan analizar información relevante de estos datos, como el nombre del financiador y el número de contrato o adjudicación, con distintos grados de éxito, como se indica a continuación:
Acción COST, FA0803 | Séptimo programa marco de la UE, - | Fundación Ricola - Cultura de la Naturaleza, -
Al considerar la discusión de las expresiones regulares de arriba, observe el enfoque en el análisis de estos datos sobre Sustantivos y Sustantivos y entradas numéricas, aunque es probable que se estén desarrollando enfoques basados en diccionarios y reconocimiento de entidades de financiamiento basado en aprendizaje automático.
Un desafío importante cuando se trata de información de financiamiento es determinar si los datos deben agruparse o no. Por ejemplo, si los fondos de la Comisión Europea en el marco de los programas marco y los de los fondos regionales o sectoriales europeos se agrupan. La respuesta a esta pregunta dependerá en parte del nivel de detalle requerido por la investigación. En general, el enfoque adoptado, como agrupar todos los fondos a nivel de la UE, debe quedar claro en una nota explicativa para el lector al presentar los resultados de los datos.
Una observación importante sobre los datos de limpieza es considerar qué tan detallada debe ser la operación de limpieza. Por ejemplo, si solo se mostrarán al lector los diez primeros o los 20 primeros resultados, es importante asegurarse de que la persona, la organización o la organización de financiamiento se hayan limpiado para capturar todas las variantes de nombre relevantes para garantizar la precisión de los recuentos.
2.5 Visualizando la literatura científica.
Una amplia gama de opciones están disponibles para visualizar datos de la literatura científica. Por lo general, esto incluirá datos básicos sobre tendencias, distribución geográfica de registros, áreas temáticas, organizaciones de alto rango e investigadores. Cuando trabaje para visualizar datos, es una muy buena idea familiarizarse con algunas de las excelentes publicaciones sobre este tema, en particular el libro clásico La visualización visual de información cuantitativa por Edward Tufte y Stephen Few (2012) Muéstreme los números: Diseñando tablas y Gráficos para Englighten .
Para ilustrar algunos enfoques para visualizar datos de la literatura científica, utilizaremos datos del informe de la OMPI sobre recursos genéticos marinos en países del sudeste asiático.
2.5.1 Dashboards
Los tableros son una forma poderosa y popular de resumir datos. La Figura 2.1 muestra un resumen de los datos generales sobre la investigación científica sobre los recursos genéticos marinos en el sudeste asiático.
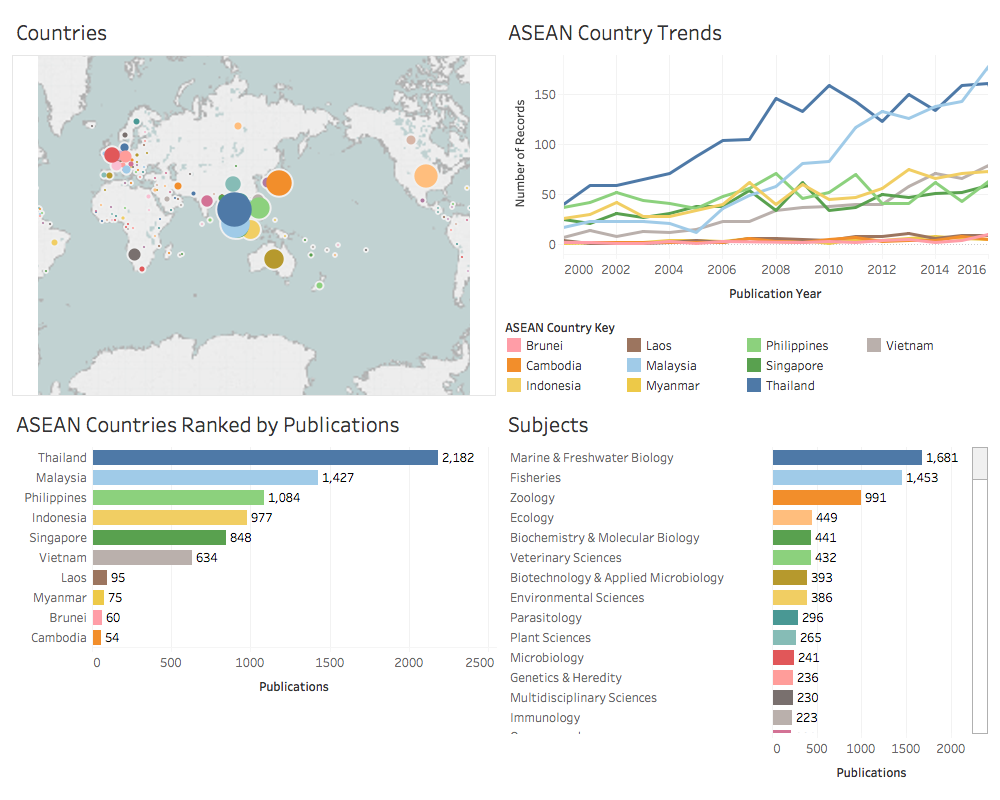
Figura 2.1: Resumen de la investigación sobre los recursos genéticos marinos en los países de la ASEAN
La Figura 2.2 muestra detalles de las especies, áreas temáticas, organizaciones y autores.
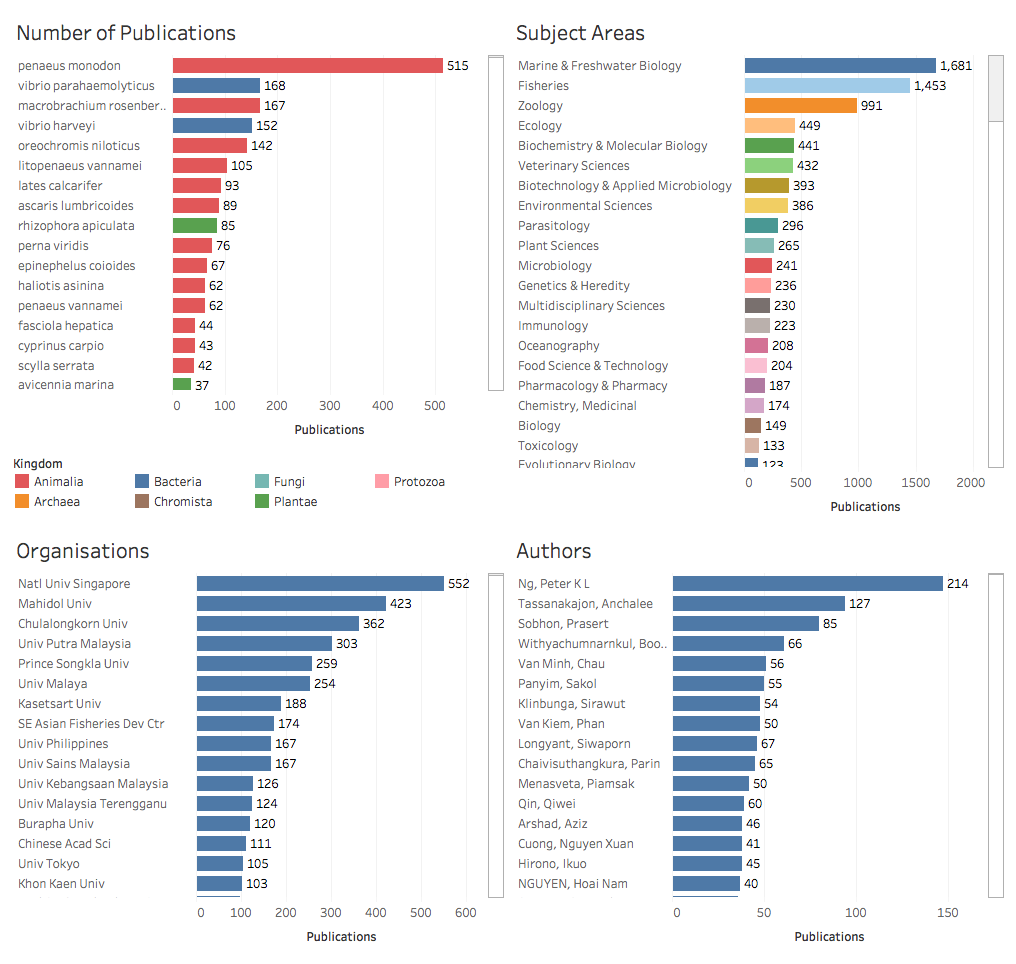
Figura 2.2: Resumen de especies marinas, organizaciones y autores
El efecto del uso de los tableros es transmitir la información objetiva principal en una forma fácilmente digerible. Como los lectores escanearán comúnmente de izquierda a derecha, el primer panel debe contener la información clave que desea transmitir. En el primer caso anterior, el objetivo del primer panel es llamar la atención sobre el hecho de que los datos provienen del sudeste asiático. En el segundo panel, el objetivo es llamar la atención sobre las especies marinas como la clave para interpretar de qué se trata la información. Tenga en cuenta que es posible que deba prestarse atención a problemas como el tamaño de las fuentes y la cantidad de paneles para comunicar los resultados al lector.
Las visualizaciones anteriores se crearon utilizando Tableau y en el Capítulo 9 del Manual de la OMPI sobre Análisis de Patentes de Fuentes Abiertas se proporciona una guía práctica para utilizar cuadros de mando utilizando el software gratuito Tableau Public.
Un problema con las visualizaciones de datos de esta manera es que son verticales. No vemos las relaciones entre las entidades en los datos cuando, en la práctica, la investigación científica se realiza comúnmente como parte de redes de colaboración en diferentes niveles. Las visualizaciones de red abordan este problema
2.5.2 Visualización de la red
La Figura 2.3 muestra una vista en red de las relaciones entre los autores involucrados en la investigación científica sobre recursos genéticos marinos en el sudeste asiático. Los puntos se clasifican según el número de publicaciones asociadas con un autor. Las líneas o bordes representan publicaciones de coautoría. La red se ha limitado a mostrar autores con 20 o más publicaciones.
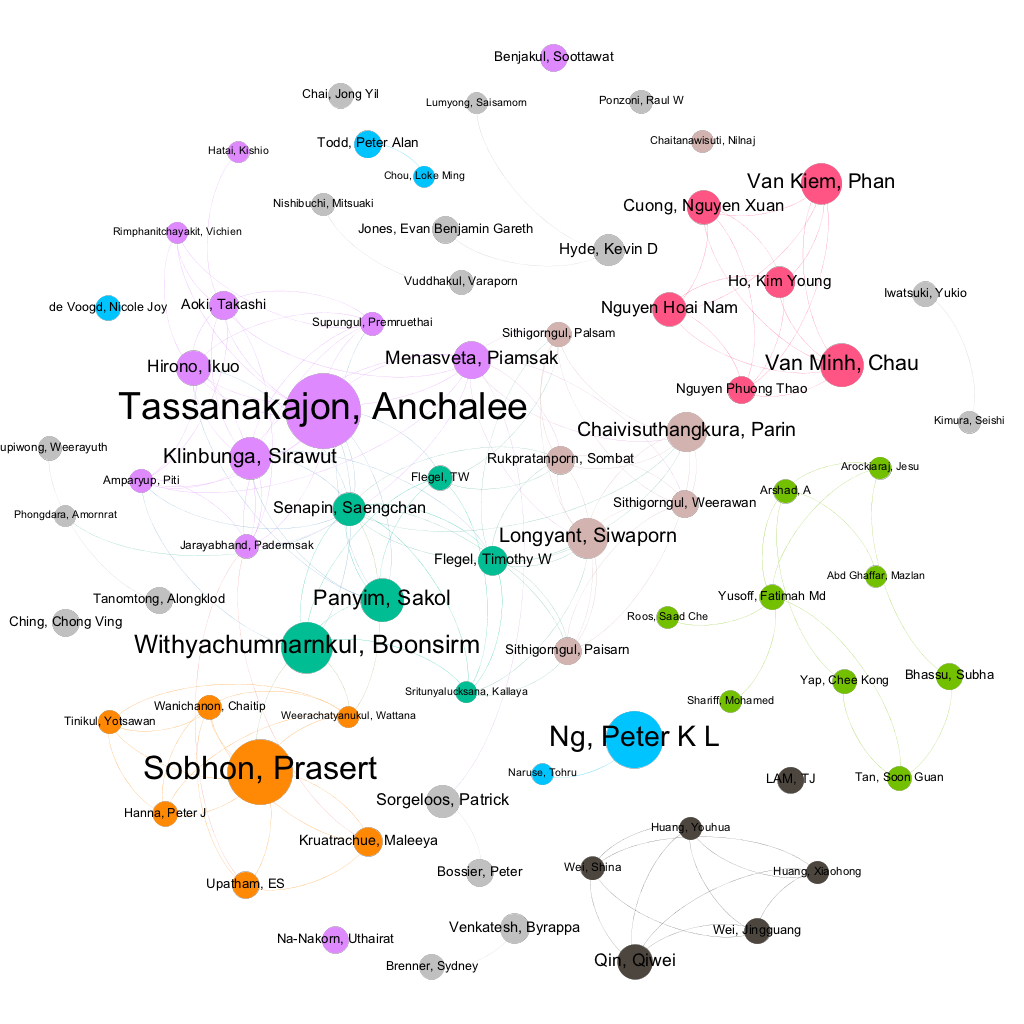
Figura 2.3: Redes de investigación para investigadores con 20 o más publicaciones sobre recursos genéticos marinos
Estas imágenes de red son importantes porque muestran relaciones que son difíciles de ver de otra manera. Un ejemplo particularmente bueno de esto son las redes de organizaciones de financiamiento como se muestra en la Figura 2.4 . Tenga en cuenta que en la Figura 2.4 el tamaño de los puntos representa el número de publicaciones en las que la agencia de financiamiento aparece en el anuncio de agradecimientos, no refleja el tamaño de las inversiones financieras. Las líneas representan publicaciones en las que aparecen diferentes agencias de financiamiento en los agradecimientos.

Figura 2.4: Red de organizaciones de financiación que apoyan la investigación sobre los recursos genéticos marinos
El alcance total de las relaciones de red suele ser invisible para los participantes de la red. Esto es particularmente cierto para las redes de organizaciones de financiación. Sin embargo, la visualización en red es una herramienta poderosa para relacionarse con investigadores y audiencias interesadas en un tema en particular. Las visualizaciones de red presentadas anteriormente se crearon utilizando el software gratuito Gephi y en el Capítulo 10 del Manual de la OMPI sobre análisis de patentes de código abierto se proporciona una guía práctica para crear estas redes .
2.5.3 Otras formas de visualización
La visualización de datos ha avanzado rápidamente en los últimos años y la biblioteca de Javascript D3 ha sido responsable de una explosión virtual en la creatividad con gráficos interactivos. Se pueden ver ejemplos de posibilidades de visualización en la galería D3 en Github https://github.com/d3/d3/wiki/Gallery . Una de otras opciones posiblemente fructíferas para la visualización de datos es el diagrama de Sankey, una forma de dendograma que tiene como objetivo mostrar el flujo de energía entre entidades. La Figura 2.5 muestra el flujo de publicaciones de investigación sobre una especie marina en el sudeste asiático en revistas por área temática.
Figura 2.5: Diagrama de Sankey que muestra los flujos de investigación sobre géneros marinos en revistas por áreas temáticas
Este tipo de visualización sirve para el útil propósito de mostrar el flujo del esfuerzo de investigación representado por las publicaciones como resultados en diferentes áreas temáticas. Una ventaja particular de esta visualización es que podemos ver la proporción de investigación sobre un género particular de organismos marinos, como los camarones en el género Penaeus, como el Langostino Gigante, en revistas sobre temas específicos. Para Penaeus, uno de los principales focos de la acuicultura en el sudeste asiático, podemos ver que el flujo de energía de investigación se canaliza hacia la pesca, la biología marina y de agua dulce y las ciencias veterinarias (para tratar enfermedades que afectan a este género comercialmente importante, como los virus en el género vibrio). Cuando se ve en línea, este diagrama es interactivo y destacará los flujos de un género en particular a un área temática.
La capacidad de crear diagramas de Sankey depende en gran medida de la voluntad de interactuar con un lenguaje de programación como Javascript, R o Python que proporciona bibliotecas para realizar los cálculos y generar los diagramas de Javascript. Por lo tanto, el diagrama anterior se generó con el paquete D3network en R. Sin embargo, varios servicios en línea ofrecen la posibilidad de crear diagramas Sankey y estos pueden satisfacer sus necesidades.
2.6 Vinculación de la literatura científica con el análisis de patentes
El análisis de la literatura científica es importante porque nos permite comprender el panorama de la investigación para un tema en particular. En el caso de la tecnología de drones, vimos que las búsquedas exploratorias podrían ayudar a identificar palabras clave para la construcción de estrategias de búsqueda más refinadas y excluir progresivamente el ruido de los resultados. En los datos que hemos presentado anteriormente sobre investigaciones sobre recursos genéticos marinos en el sudeste asiático, procesamos los datos para responder a las siguientes preguntas fundamentales:
- ¿Quién (y con quién?)
- Qué
- Dónde
- Cuando
- Cómo
Estas son preguntas estándar en la investigación empírica. La pregunta final requiere atención detallada a la literatura en sí misma en términos de comprender el tema preciso de la investigación por parte de un individuo en particular o un equipo de investigación. Sin embargo, este tipo de análisis de paisaje nos permite investigar si la investigación tiene el potencial de transformarse en un producto, método o proceso comercial y, por lo tanto, nos lleva a la patente y al sistema de propiedad intelectual más amplio.
Este tipo de investigación puede ser útil en diferentes niveles:
- Las universidades pueden estar interesadas en identificar resultados de investigación que puedan tener potencial para convertirse en productos, métodos o procesos útiles.
- Las compañías activas en sectores particulares pueden estar buscando desarrollar nuevos productos y están buscando identificar investigaciones existentes relevantes.
- Las agencias de financiamiento pueden estar tratando de comprender los resultados existentes de las inversiones en investigación e identificar áreas relevantes de investigación prioritaria que prometen dar como resultado productos nuevos y útiles.
En muchos casos, el análisis del panorama científico se llevará a cabo a un nivel inferior al de los diez países cubiertos por la investigación sobre los países del sudeste asiático mencionados anteriormente. Sin embargo, este ejemplo ilustra la posibilidad de utilizar estos métodos y enfoques para responder preguntas empíricas a escala y luego profundizar en el detalle detallado de la investigación.
Una pregunta importante que surge aquí es cómo vincular la investigación sobre la literatura científica con la investigación en el sistema de patentes. Hay dos respuestas principales a esto.
- Utilizar palabras clave y frases identificadas en la investigación de la literatura científica como base para las búsquedas de la literatura de patentes.
Este es probablemente el enfoque más común. Como se discutió anteriormente, el acceso a secciones de la literatura, como títulos, resúmenes y palabras clave de autor, permite la aplicación de métodos básicos de minería de textos para dividir textos en palabras y frases. Esto a su vez permite que la literatura sea clasificada y refinada para identificar objetivos de interés. En software como VantagePoint esto se hace comúnmente al ordenar los datos en grupos. Por ejemplo, en el caso de la tecnología de aviones no tripulados, un área importante de investigación se centra en los sensores, mientras que otra área de investigación se centra en los dispositivos inalámbricos para suministrar energía a un avión no tripulado, mientras que la tercera se centra en dispositivos como auriculares y otros dispositivos para controlar un avión no tripulado. vuelo.
- Enfocarse en identificar investigadores individuales que estén activos en un campo de investigación que también estén activos en el sistema de patentes
Este enfoque para vincular la investigación científica con los datos de patentes es más raro por la razón directa de que es mucho más difícil de hacer a escala que un enfoque que utiliza palabras clave. Sin embargo, tiene la ventaja de proporcionar una visión más clara de los investigadores que ya están activos en investigación y desarrollo comercial con un alto grado de precisión.
2.6.1 Mapeo de autores a inventores
Los investigadores identificadores que están activos en el sistema de patentes involucran un proceso de tres pasos
- Unir un conjunto de datos con la literatura científica a un conjunto de datos de patente y combinar los campos de nombre del autor y el inventor.
- Identificar los criterios de coincidencia para establecer si un autor e inventor son la misma persona
- Aplicar los criterios de coincidencia para llegar a un conjunto de datos que incluya a los autores que también son inventores.
- Revisión y resumen de los datos.
El primer paso en el proceso implica identificar el enfoque apropiado para crear un conjunto de datos de patentes. Esto podría implicar el uso de un amplio conjunto de términos para capturar el universo probable de la actividad de patentes utilizando la literatura científica como una guía para la selección de términos. Por ejemplo, en el caso de la tecnología de aviones no tripulados, sería lógico crear un conjunto de datos de trabajo utilizando los términos descritos anteriormente, como vehículos no tripulados y vehículos aéreos no tripulados. El problema principal aquí es la difusión de la red lo suficientemente amplia como para capturar el universo de actividad, al mismo tiempo que reduce los datos lo suficiente para evitar el uso de un vasto conjunto de datos.
Para la investigación sobre la actividad a nivel nacional, como en el caso del paisaje para la investigación sobre los recursos genéticos marinos en el sudeste de Asia, el enfoque adoptado fue identificar la actividad de patentes de las colecciones nacionales y la actividad de patentes en todo el mundo vinculada a un inventor o solicitante del sudeste asiático. seguido por el texto que extrae los datos de las especies marinas y que trata esos datos como el conjunto de datos de trabajo Este enfoque requería acceso a los datos de patentes a escala y la capacidad de procesar esos datos (realizados en VantagePoint y R).
VantagePoint es una herramienta importante para unir conjuntos de datos de diferentes tipos y crear un campo común. Por lo tanto, en la investigación sobre el sudeste asiático, los datos científicos y los datos de patentes se combinaron en un conjunto de datos. En el siguiente paso, el campo del nombre completo de los autores y el campo del nombre del inventor se combinaron. En ambos casos los nombres habían sido limpiados previamente. En el caso de la literatura científica, hubo un total de 17,625 nombres y en el caso de los datos de patentes hubo 9,832 nombres.
El siguiente paso en el enfoque es el uso de criterios de coincidencia. En este caso se utilizaron los siguientes criterios.
- Un autor y un coautor aparecieron como inventores en el mismo documento de patente.
- El nombre de un autor y la organización enumerada como solicitante coincidieron con la afiliación del autor.
- El nombre del autor y el nombre de la especie marina aparecieron en la publicación científica y en el documento de patente.
El propósito de estos criterios es identificar a los autores-inventores y es importante tener en cuenta que el tercer criterio de coincidencia puede variar de un conjunto de datos a otro. El punto importante es identificar y utilizar criterios de coincidencia. Para calificar como un autor inventor, el registro debía cumplir al menos uno y preferiblemente dos de los criterios anteriores. La experiencia ha revelado que los nombres de los coautores que aparecen como inventores son los criterios de coincidencia más precisos. Una excepción a esto son los nombres de Asia oriental, donde, de acuerdo con las prácticas tradicionales de nomenclatura, los nombres de co-autores e inventores pueden ser muy comunes. Esto puede dar lugar a falsas coincidencias positivas y, por lo tanto, es importante aislar estos casos para probarlos con los otros criterios de coincidencia.
Como se mencionó anteriormente, un método útil para trabajar con grandes cantidades de datos es asignar registros para mantener, revisar y excluir grupos y adoptar un método de múltiples pases. Al final de la primera pasada, el grupo de revisión generalmente será grande porque marca aquellos casos en los que hubo un elemento de incertidumbre en los criterios de coincidencia. Por ejemplo, donde los nombres del autor y el coautor parecen coincidir con los inventores pero son nombres muy comunes. Alternativamente, el primer criterio podría haberse cumplido pero los registros de afiliación y organización no coincidieron. Finalmente, para revisión, incluya los casos en los que hay un autor para hacer coincidir con el inventor pero solo se comparten los nombres de las especies. Durante el segundo y potencialmente varios otros pases, el grupo de revisión se asigna progresivamente a mantener o excluir.
Al final del proceso, se identificaron un total de 290 autores de investigaciones sobre recursos genéticos marinos en el sudeste asiático que también son inventores. Como esto sugiere, el desarrollo de este tipo de análisis implica la revisión de un gran número de registros con la expectativa de un bajo número de resultados. Una ventaja particular del uso de los criterios de coincidencia es que limita la alta probabilidad de coincidencias falsas positivas si no se usan los criterios de coincidencia.
Como esto también sugiere que los investigadores de mapeo de la literatura científica en la literatura de patentes pueden consumir mucho tiempo. Este es un problema particular cuando la investigación es a gran escala, como el nivel de millones de registros. El problema de la desambiguación de nombres y los desafíos correspondientes con la limpieza de nombres han demostrado ser un desafío persistente tanto en la literatura científica como en la literatura de patentes. Sin embargo, hay indicios de que la situación puede estar mejorando, al menos, incluso si no se resuelve.
En el caso de la literatura científica, el crecimiento de identificadores de ORCID gratuitos promete ayudar a mejorar pero no resolver el desafío de la desambiguación de nombres. En el momento de redactar este documento, se han emitido más de 5 millones de identificadores ORCID y un número creciente de organizaciones de financiación y editores están solicitando o solicitando un identificador ORCID. Clarivate Analytics también ha hecho que la relación entre su sistema de identificación de investigadores de larga data y ORCID sea perfecta. En un movimiento innovador, la Base de datos de patentes de lentes ahora alienta a los investigadores-inventores a asociar su ORCID. Además, The Lens ha vinculado más de 10 millones de citas bibliográficas no relacionadas con patentes a registros de ORCID para que los investigadores puedan ver la literatura de patentes que cita su investigación.
En otro desarrollo en 2015, la USPTO organizó un Taller de Desambiguación de Inventores para discutir el problema de la desambiguación de nombres de inventores. 5 Como resultado de una competencia organizada por la USPTO, un equipo de la Universidad de Massachusetts Amherst liderado por Andrew McCallum y Nicholas Monath desarrolló un algoritmo utilizando una referencia jerárquica discriminativa o, en esencia, un modelo de árbol de decisión para agrupar nombres de inventores basados en referencias a otros datos. campos en el registro (para una descripción detallada del enfoque, consulte Wick, Singh y McCallum 2012 ). El resultado de esta investigación se aplicó tanto al campo de inventor y cesionario de la USPTO como a la creación de nuevas tablas con enlaces a las tablas sin procesar originales. Si bien no se espera que esté libre de errores, las tablas de datos de PatentsView pueden ofrecer oportunidades para establecer más fácilmente vínculos entre los datos de la literatura científica y los datos de patentes, al menos para los datos de la USPTO, ya que está disponible de forma gratuita y se ha procesado previamente.
La capacidad de hacer coincidir los nombres entre la literatura científica y la literatura de patentes a escala sigue siendo un desafío significativo y que requiere mucho tiempo. Sin embargo, en el caso de los países de la ASEAN, reveló autores-inventores como Baldomera Olivera, de Filipinas, quien fue pionero en la investigación sobre toxinas de caracol cónico que aparecería en la portada de la revista Science y conduciría a un producto farmacéutico aprobado. Otros investigadores identificados a través de este enfoque incluyeron al equipo de esposo y esposa Hu Bow y Ding Jeak Ling de la Universidad Nacional de Singapur, quienes identificaron un factor de ADNc recombinante del cangrejo de herradura que ahora se usa en ensayos de endotoxinas y biosensores. En resumen, el enfoque proporciona evidencia detallada de investigadores que han otorgado con éxito invenciones con licencia que se han convertido en productos en el mercado.
En la práctica, la mayor parte de la actividad de investigación no da como resultado una actividad de patente. Sin embargo, combinar el análisis de la literatura científica con la literatura de patentes puede llevar a la identificación de posibles candidatos para el desarrollo y ejemplos de licencias exitosas de investigación e invenciones que pueden servir como ejemplos positivos para investigadores y responsables políticos en otros lugares.
Cerraremos esta discusión de métodos y enfoques para vincular el análisis de la literatura científica y de patentes con un desarrollo reciente para vincular citas de literatura y datos de patentes.
2.7 Vinculación de citas con la literatura de patentes
Una forma alternativa de pensar acerca de la relación entre la literatura científica y la actividad de patentes es centrarse en citas de literatura que no sean de patentes (Callaert, Van Looy, et al. 2006 ) . En un desarrollo reciente, la base de datos de patentes de acceso abierto de Lens ha realizado un extenso trabajo para vincular los identificadores de documentos en la literatura no relacionada con patentes a la base de datos de metadatos Crossref en más de 96 millones de publicaciones y para vincular registros con PubMed y Microsoft Academic. El efecto es crear un puente basado en identificadores entre la literatura científica y de patentes. Figura 2.6
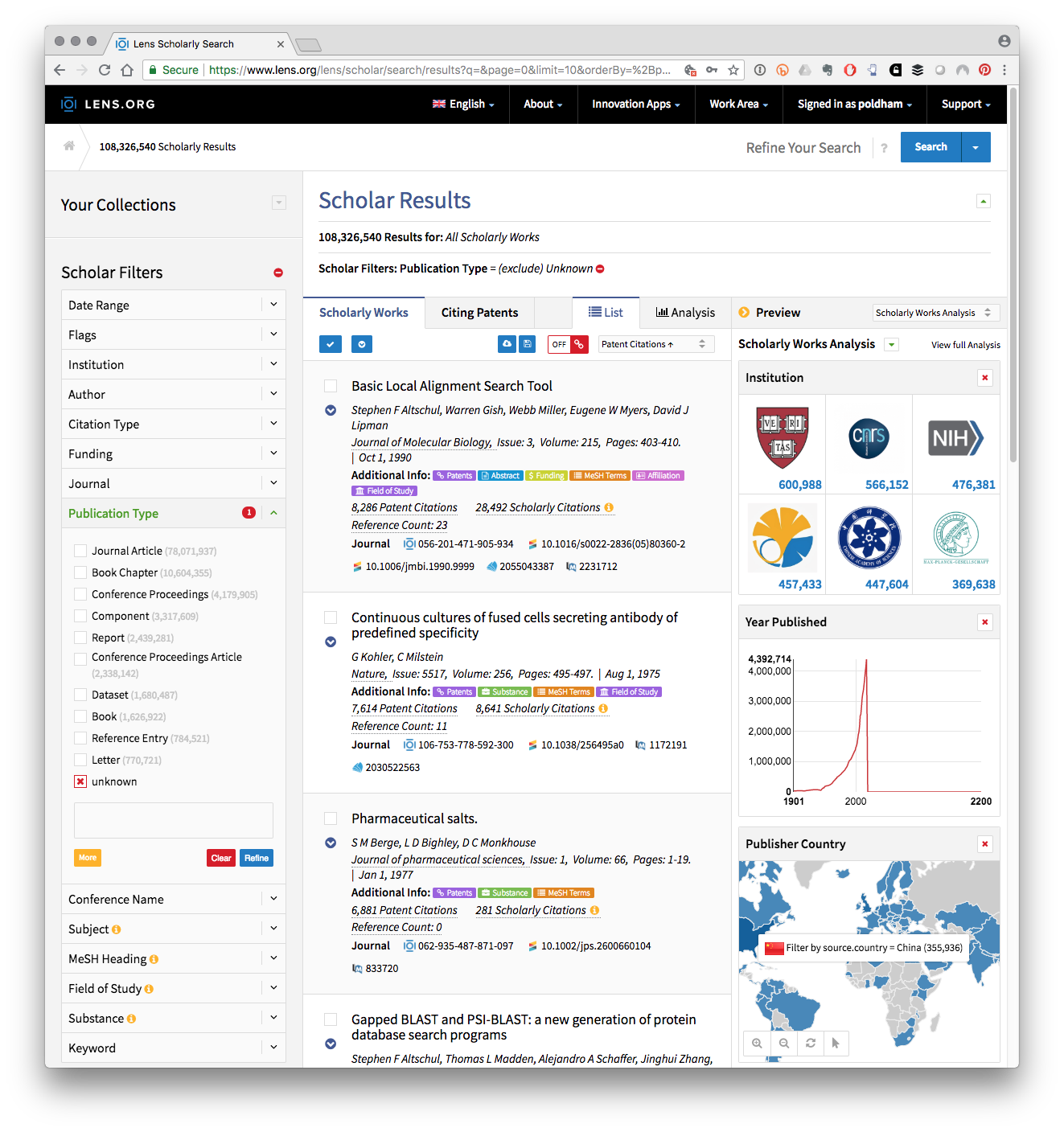
Figura 2.6: Citas de literatura vinculadas a citas de patentes y fuentes de datos externas en la lente
Esta figura muestra la cita bibliográfica de mayor rango en los datos de la conocida herramienta de búsqueda de alineación local básica o BLAST que se usa ampliamente en campos como la genómica. Los enlaces de cada entrada a una tabla de resumen incluyen los términos de los títulos de temas médicos (MeSH, por sus siglas en inglés) cuando corresponda, y una página de citas que revelará las citas de patentes y citas de literatura. Usuarios registrados, el registro es gratuito, puede almacenar y luego exportar los resultados. La Tabla 2.5 presenta una muestra de campos del top 5 de los 9000 resultados exportados de una búsqueda de Lens Scholar para "biología sintética".
Tabla 2.5: Lens Scholar Exportó Resultados para Biología Sintética
| Título | Referenciado por el Conteo de Patentes | Año de publicación | ID de citas | Autor / es |
| Síntesis de genes múltiplex precisa a partir de microchips de ADN programables. | 188 | 2004 | (magid) mag2027912527;(doi) 10.1038 / nature03151; (pmid) 15616567 | Jingdong Tian; Hui Gong; Nijing Sheng;Xiaochuan Zhou;Erdogan Gulari;Xiaolian Gao; Iglesia de George M. |
| Rutas biosintéticas de novo: diseño racional de fábricas de microbios químicos. | 91 | 2008 | (pmid) 18725289;(magid) mag2092471565;(doi) 10.1016 / j.copbio.2008.07.009 | Kristala LJ Prather;Collin H. Martin |
| Aprovechamiento de la recombinación homóloga in vitro para generar ADN recombinante a través de SLIC. | 81 | 2007 | (doi) 10.1038 / nmeth1010; (pmid) 17293868; (magid) mag2102440675 | Mamie Z. Li;Stephen J. Elledge |
| Síntesis de PicoArray microfluídica de oligodesoxinucleótidos y ensamblaje simultáneo de múltiples secuencias de ADN | sesenta y cinco | 2004 | (pmcid) pmc524290;(pmid) 15477391;(magid) mag2146545072;(doi) 10.1093 / nar / gkh879 | Xiaochuan Zhou; Shi-Ying Cai;Ailing Hong;Qimin You;Peilin Yu;Nijing Sheng;Onnop Srivannavit;Seema Muranjan;Jean Marie Rouillard;Yongmei Xia;Xiaolin Zhang; Qin Xiang;Renuka Ganesh; Qi Zhu; Anna Matejko;Erdogan Gulari;Xiaolian Gao |
| Gene Designer: una herramienta de biología sintética para construir segmentos de ADN artificiales. | 59 | 2006 | (pmcid) pmc1523223; (pmid) 16756672; (magid) mag1760665500;(Doi) 10.1186 / 1471-2105-7-285 | Alan Villalob |
Como lo sugiere, las tendencias crecientes hacia la federación de la literatura científica y de patentes presentan oportunidades importantes para diseñar estrategias de búsqueda y enfoques más flexibles para el análisis y la comunicación de resultados basados en la literatura científica y de patentes.
2.8 Conclusión
Este capítulo se centra en los métodos para trabajar con datos de la literatura científica, utilizando el análisis de la literatura científica para desarrollar una estrategia de búsqueda, el desarrollo de un estudio científico del paisaje y los métodos para vincular la literatura científica con el análisis de patentes.
Referencias
Bola, rafael. 2018. Una introducción a la bibliometría . Elsevier https://doi.org/10.1016/c2016-0-03695-1 .
Fellbaum, Christiane. 2015. WordNet . Editado por Susan EF Chipman. Prensa de la Universidad de Oxford. https://doi.org/10.1093/oxfordhb/9780199842193.013.001 .
Jones, Karen Sparck. 1972. "Una interpretación estadística de la especificidad de los términos y su aplicación en recuperación". Diario de documentación 28 (1): 11–21. https://doi.org/10.1108/eb026526 .
Leydesdorff, Loet e Ismael Rafols. 2009. "Un mapa global de la ciencia basado en las categorías de temas ISI". Revista de la Sociedad Americana para la Ciencia y Tecnología de la Información 60 (2): 348–62. https://doi.org/10.1002/asi.20967 .
Wick, Michael, Sameer Singh y Andrew McCallum. 2012. "Un modelo jerárquico discriminatorio para la referencia rápida en gran escala". En los procedimientos de la 50ª Reunión Anual de la Asociación de Lingüística Computacional: Documentos Largos - Volumen 1 , 379–88. ACL '12. Stroudsburg, PA, EE. UU .: Asociación para la lingüística computacional. http://dl.acm.org/citation.cfm?id=2390524.2390578 .
Callaert, Julie, Bart Van Looy, Arnold Verbeek, Koenraad Debackere y Bart Thijs. 2006. "Trazas de la técnica anterior: un análisis de referencias no de patente encontradas en los documentos de patente". Scientometrics 69 (1): 3-20. https://doi.org/10.1007/s11192-006-0135-8.
-
Jeffrey Friedl, fuente de la famosa cita de "Ahora tienes dos problemas" http://regex.info/blog/2006-09-15/247 ↩
-
Vea, por ejemplo, la Basic Regular Expressions in RHoja de trucos de Ian Kopacka disponible de RStudio ↩
-
Este ejemplo está adaptado de la entrada de Wikipedia en https://en.wikipedia.org/wiki/Precision_and_recall ↩
-
El archivo de livestream del taller está disponible en https://livestream.com/uspto/PatentsViewInventorWorkshop ↩
Capítulo 3 Conteo de datos de patentes
Este capítulo proporciona una introducción en profundidad al desarrollo de estadísticas de patentes descriptivas. El recurso existente más importante para el desarrollo de estadísticas de patentes es el Manual de estadísticas de patentes de la OCDE y una serie de documentos de trabajo de la OCDE ( Manual de estadísticas de patentes de la OCDE 2009 ) . Sin embargo, ha faltado una guía práctica paso a paso para el desarrollo de conteos de patentes utilizando datos del mundo real. Este capítulo apunta a llenar este vacío al trabajar desde el análisis de la estructura de los números de patentes hasta la creación de cuentas de prioridad o las primeras presentaciones. A esto le sigue la exploración de las familias de patentes y concluye con una gráfica de las tendencias de patentes.
El Capítulo hace un uso extensivo del conjunto de datos de patentes de drones . El conjunto de datos de drones es un conjunto de documentos de patente relacionados con el término drone o drones creados como un conjunto de datos de juguete o entrenamiento para experimentos en el desarrollo de estadísticas de patentes. Las instrucciones sobre cómo instalarlo se proporcionan en la sección Cómo usar el manual al principio del libro y en la página de inicio del conjunto de datos .
3.1 La estructura de los números de patente.
Los números de patente son los identificadores clave para los documentos de patente. Al momento de escribir este documento, actualmente hay 107 millones de patentes y documentos relacionados dentro de la oficina central de la Oficina Europea de Patentes (DOCDB). La clave para trabajar y contar estos documentos es comprender la estructura de los números de patentes.
La Tabla 3.1 presenta los principales números de patentes, ya que comúnmente se recuperan de las bases de datos de patentes.
| fila | número de prioridad | Numero de aplicacion | número de publicación |
|---|---|---|---|
| 1 | US2016578323F 2016-09-20 | US2016578323F 2016-09-20 | USD801224S1 |
| 2 | US15360203A 2016-11-23 | US15360203A 2016-11-23 | US9807726B1 |
| 3 | US62133061P 2015-03-13 | US15069675A 2016-03-14 | US9804596B1 |
| 4 | US14622134A 2015-02-13 | US14622134A 2015-02-13 | US9802728B1 |
| 5 | JP2015122335A 2015-06-17;WO2016JP67809A 2016-06-15 | US15322008A 2016-12-23 | US9802691B2 |
| 6 | US15346251A 2016-11-08 | US15346251A 2016-11-08 | US9805273B1 |
Para cada uno de estos números observamos la siguiente estructura.
- Un código de país de dos letras, como EE. UU. (Estados Unidos) o KR (Corea del Sur)
- Un identificador numérico que, para años más recientes, puede incluir el año, por ejemplo, 2016578323 o 15263985
- Una letra o combinación de una letra y un número como A, A1, B1, B2, S o P que denota lo que se llama el código Kind para el documento
- La fecha en el formato Año - Mes - Día (conocido como AAAA-MM-DD)
Es importante tener en cuenta que los números de patentes recuperados de las bases de datos de patentes no se presentan necesariamente en la forma en que se almacenan. Por ejemplo, el código de país, el identificador numérico, el código de tipo y la fecha a menudo se almacenan en columnas separadas y luego se combinan. Cuando se trabaja con diferentes bases de datos, esto se puede reflejar en espacios entre el código del país, el número y el código del tipo. Además, las entradas originales en los formularios de solicitud de patente a menudo incluyen barras diagonales./. En algunos casos, las bases de datos presentarán números que contengan el carácter de barra diagonal y en otros se eliminarán, ya que no se agregan al carácter distintivo del identificador. Tenga en cuenta que algunas bases de datos de patentes, como Notable Derwent Innovation de Clarivate Analytics, agregan 000s de relleno en medio de algunos números de patentes para que sean uniformes y pueden agregar el campo del año al comienzo de los números de patentes. Por esta razón, el uso de números de patentes en diferentes bases de datos no es tan sencillo como podría ser. Las leves variaciones en el formato serán la razón más común por la que se encuentra un número de patente en una base de datos pero no en otra.
3.1.1 El código del país
El código de país de dos letras denota el país de presentación, el país de solicitud o el país de publicación. Por ejemplo, en la fila 5 de la Tabla 3.1 anterior, JP2015122335A 2015-06-17 se presentó primero como una solicitud en Japón y luego pasó al Tratado de Cooperación de Patentes como WO2016JP67809A 2016-06-15 (donde WO denota el Tratado de Cooperación de Patentes) . Esa solicitud se presentó como US15322008A 2016-12-23 en los Estados Unidos y se publicó como US9802691B2. Una lista completa de los códigos de país de dos letras, incluidos los códigos para el Tratado de Cooperación en materia de Patentes (WO) y los instrumentos regionales, está disponible en laEl Manual de la OMPI sobre información y documentación en materia de propiedad industrial con arreglo a la norma ST.3 Recomendación sobre códigos de dos letras para la representación de Estados, otras entidades y organizaciones intergubernamentales . La misma tabla también está disponible en Wikipedia . Las herramientas de software como VantagePoint proporcionan tesauros que convertirán los códigos de país en nombres de países.
Los códigos de país nos dicen dónde se archiva y publica un documento. Esto proporciona la base para identificar tendencias por país utilizando una variedad de conteos diferentes y para el mapeo geográfico.
3.1.2 El identificador numérico
El segundo elemento de un número de patente es un identificador numérico. Como se señaló anteriormente, es importante tener en cuenta que estos identificadores pueden ser editados por bases de datos. Por ejemplo, el Índice de Patentes Mundial de Derwent a menudo usa un solo o un cero de relleno entre el año en un campo y el número. Probablemente esto se debió a un esfuerzo por hacer que los números de patente tengan una longitud uniforme, pero tiene el efecto de que estos documentos no pueden recuperarse fácilmente de las bases de datos que no usan ceros de relleno (como esp @ cenet ). En otros casos, los números pueden incluir caracteres como "/" que no forman parte formalmente del identificador. El código tipo también se puede agregar en algunas bases de datos pero no en otras.
3.1.3 Códigos de clase
Los códigos de clase aparecen como combinaciones de letras y números después del identificador numérico. Los códigos amables describen el tipo de documento y el nivel de publicación. Los códigos de tipo se documentan en la Norma ST.16 de la OMPI Código estándar recomendado para la identificación de diferentes tipos de documentos de patente . Formalmente hablando, los códigos amables se aplican a:
"Patentes de invención, certificados de inventor, patentes de medicamentos, patentes de plantas, patentes de diseño, certificados de utilidad, modelos de utilidad, patentes o certificados de adición, certificados de adición de utilidad y aplicaciones publicadas correspondientes" (WIPO ST.16 página 3.16.1, Octubre 2016)
En relación con el nivel de publicación, la definición explica que:
"Un" nivel de publicación "se define como el nivel correspondiente a una etapa procesal en la que normalmente se publica un documento en virtud de una ley nacional de propiedad industrial determinada o de una convención o tratado regional o internacional de propiedad industrial"
Entonces, para tomar un ejemplo común, se puede publicar un documento de patente en la etapa de solicitud. Esta es comúnmente la primera etapa procesal y es el primer nivel de publicación. En muchos países, las solicitudes de patente estándar recibirán el código de clase A en este primer nivel de publicación. En muchos países, cuando se otorga una patente, el documento ingresa al segundo nivel de publicación y se publica con el código de clase B. Otros tipos de documentos de patentes comúnmente reciben sus propios códigos de clase que indican su tipo. Por ejemplo, los modelos de utilidad reciben el código de clase U mientras que las patentes de diseño reciben el código de clase S.
Los códigos amables suelen ir acompañados de un número que agrega información adicional sobre el tipo de documento. Dentro del estándar de la OMPI, estos números van del 1 al 7, con los números 8 y 9 reservados para correcciones a los datos bibliográficos (por ejemplo, A8) o a cualquier parte del documento (por ejemplo, A9). Los ejemplos y tipos de documentos de patente de la OMPI forman parte del Manual de la OMPI sobre información y documentación en materia de propiedad industrial en el que se establecen los códigos comunes y se recomienda su lectura a los analistas de patentes. Clarivate Analytics y las oficinas nacionales de patentes también producen tablas de referencia rápida y están disponibles en línea.
El uso de códigos de tipo de patente ha evolucionado con el tiempo y esto puede dificultar la interpretación precisa de un código de tipo. En la práctica:
- El uso de un código amable puede variar en el mismo país a lo largo del tiempo. Por ejemplo, en los Estados Unidos, antes de 2001, las patentes solo se publicaron cuando se otorgaron (primer nivel de publicación) y se les otorgó el código de clase A. A partir de 2001, Estados Unidos adoptó la práctica común en otros lugares y las solicitudes publicadas que ahora reciben el código de clase A ( como primer nivel de publicación), mientras que las concesiones de patentes son ahora el segundo nivel de publicación (y reciben el código de clase B);
- El uso de códigos amables varía entre países.
Como regla general, las publicaciones con código de clase A comúnmente significan la publicación de una aplicación. Las publicaciones con código de clase B significan la publicación de una concesión de patente. Pero, esto no siempre es cierto y solo se puede describir como una regla general aproximada. Normalmente, esta regla se puede utilizar cuando se trabaja con datos de las principales jurisdicciones, como los Estados Unidos (teniendo en cuenta los cambios anteriores y posteriores a 2001 que se consideran a continuación), la Oficina Europea de Patentes y el Tratado de Cooperación de Patentes (que solo cubre publicaciones de primer nivel o aplicaciones) y Japón. Sin embargo, cuando se trabaja con datos a nivel de país para elaborar tendencias para solicitudes y subvenciones, es importante revisar el uso de códigos de tipo en cada país a cubrir e identificar cambios en el uso de códigos de tipo a lo largo del tiempo.
Los códigos de tipo de patente que indican el nivel de publicación y el tipo de documento (por ejemplo, U) son importantes para fines estadísticos porque permiten la identificación de duplicados y, según el propósito del análisis, la eliminación de tipos de datos no deseados (como los modelos de Utilidad, Patentes de diseño y patentes de plantas) o el aislamiento de tipos específicos de documentos. Para la mayoría de los propósitos, los códigos de tipo son importantes para identificar solicitudes de patentes y subvenciones y críticamente para identificar las repúblicas del mismo documento (duplicados)
Los códigos de tipo más comunes que se encuentran en los datos de patentes son:
Primer nivel de publicación (comúnmente, pero no exclusivamente, solicitudes de patente)
- A1
- A2
- A3
Segundo nivel de publicación (comúnmente pero no exclusivamente patentes subvenciones)
- B1
- B2
- B3
Esto significa, para tomar un ejemplo ficticio de la USPTO y sus códigos comunes , que:
- US1234A1 Publicación de Solicitud de Patente
- US1234A2 Publicación de solicitud de patente (republicación)
- Publicación de solicitud de patente US1234A9 (publicación corregida)
- Patente otorgada por US1234B1 (no publicada anteriormente como solicitud de patente)
- Patente otorgada por US1234B2 (publicada anteriormente como solicitud de patente)
En este ejemplo, tenemos 3 publicaciones potenciales de la misma solicitud y una publicación de una concesión de patente (aunque las correcciones de una patente concedida son posibles). Con el fin de contar los datos de patentes, la forma en que tratamos estas repeticiones o duplicados depende de la pregunta que intentamos responder.
Si quisiéramos identificar la aplicación prioritaria más cercana a la inversión en investigación y desarrollo, elegiríamos el número de solicitud más antiguo disponible (que puede o no haber sido publicado). En otros casos, podemos querer contar todas las solicitudes que se derivan de una primera presentación o conjunto de solicitudes, mientras que en otros podemos identificar solicitudes y subvenciones, pero eliminar las republicaciones administrativas (simples republicaciones y correcciones o publicación del informe de búsqueda internacional) del cuenta.
El principal problema que surge aquí es determinar qué queremos incluir y excluir de los conteos. Un enfoque general de este problema es simplemente eliminar todas las publicaciones del mismo documento (cuente el documento solo una vez lo antes posible en la serie) . Por ejemplo, si estuviéramos interesados en contar las solicitudes de patentes y las concesiones de patentes en los Estados Unidos contaríamos US1234A1 y contaríamos la concesión de patentes (US1234B2) y excluiríamos las repúblicas de la solicitud. Si solo estamos interesados en contar las solicitudes de patentes, podríamos simplemente eliminar el tipo de código que indica los diferentes niveles de publicación para contar el documento US1234 solo uno. En la práctica, las estadísticas de patentes básicas comúnmente involucran el uso de múltiples métodos de conteo, como veremos con más detalle a continuación.
Como se explica en la discusión anterior al trabajar con datos de patentes para elaborar recuentos de patentes, debemos abordar los efectos multiplicadores . Estos toman dos formas principales:
- Replantación del mismo documento básico en la misma jurisdicción que las solicitudes, subvenciones, o con modificaciones como continuaciones, continuaciones en parte o divisionales.
- Presentación de solicitudes en virtud de los instrumentos regionales de patente o el Tratado de Cooperación en materia de Patentes (WO) y su nueva publicación como solicitudes, subvenciones, otras publicaciones administrativas o divisionales (en las jurisdicciones pertinentes).
Por lo tanto, en virtud del Tratado de Cooperación en materia de Patentes, un solicitante puede presentar la misma solicitud de patente para su consideración en hasta 152 Estados contratantes. En la práctica esto es raro, pero en teoría una sola solicitud podría llevar a la publicación del mismo documento como una solicitud y otorgar 304 veces (suponiendo una publicación única de una solicitud y la publicación de una subvención en cada país). Si bien este sería un caso muy inusual, revela los posibles efectos multiplicadores en los recuentos de patentes introducidos por instrumentos regionales como el Convenio Europeo de Patentes y el Tratado de Cooperación en materia de Patentes. Como veremos a continuación, en algunos casos, un solo documento puede estar vinculado a más de 1000 publicaciones.
3.2 Preparación para contar datos de patentes
Los identificadores de patentes discutidos anteriormente proporcionan la clave para rastrear documentos de patentes en todo el mundo, utilizando el concepto de familias de patentes discutido a continuación, y para elaborar recuentos de patentes. La información individual más importante cuando se piensa en los recuentos de patentes mediante identificadores es que los datos de patentes implican efectos multiplicadores que a menudo llevan a la duplicación o la nueva publicación del mismo documento o un documento que se ha modificado en base a una versión anterior.
Los identificadores de patentes proporcionan la base para navegar por estos efectos multiplicadores y la base de los recuentos de patentes comúnmente consiste en eliminar duplicados o deduplicación en diferentes niveles o combinar documentos de varias maneras.
Usaremos el conjunto de datos de drones como un ejemplo de esto. La tabla 3.2 muestra una muestra de diferentes números de patentes.
Tabla 3.2: Prioridad, solicitudes, publicación y miembros de la familia INPADOC
| fila | número de prioridad | Numero de aplicacion | número de publicación | inpadoc_family_members |
| 9 | US2016620248F 2016-09-02 | US2016620248F 2016-09-02 | USD800603S1 | USD800603S1 20171024 |
| 10 | US14835329A 2015-08-25 | US14835329A 2015-08-25 | US9801234B2 | US20170064599A1 20170302; US9801234B2 20171024 |
| 11 | US15174819A 2016-06-06 | US15174819A 2016-06-06 | US9800796B1 | US9800796B1 20171024 |
| 12 | US14530548A 2014-10-31;US2013898275P 2013-10-31 | US14530548A 2014-10-31 | US9800517B1 | US9800517B1 20171024 |
| 13 | US2015274112P 2015-12-31;US2016341797A 2016-11-02;US2016341809A 2016-11-02;US2016341813A 2016-11-02;US2016341818A 2016-11-02;US2016341824A 2016-11-02;US2016341831A 2016-11-02;US62274112P 2015-12-31 | US15341809A 2016-11-02 | US9800321B2 | CN106878672A 20170620;CN106982345A 20170725;CN107040754A 20170811;CN107046710A 20170815;CN107070531A 20170818;CN107071794A 20170818;CN206481394U 20170908;CN206517444U 20170922;EP3188474A1 20170705;EP3188475A1 20170705;EP3188476A1 20170705;EP3188477A1 20170705;EP3190788A1 20170712;EP3190789A1 20170712;US20170193556A1 20170706;US20170193820A1 20170706;US20170195038A1 20170706;US20170195048A1 20170706;US20170195627A1 20170706;US20170195694A1 20170706; US9786165B2 20171010; US9800321B2 20171024;WO2017114496A1 20170706;WO2017114501A1 20170706;WO2017114503A1 20170706;WO2017114504A1 20170706;WO2017114505A1 20170706;WO2017114506A1 20170706 |
Podemos ver aquí que uno o más números de prioridad están vinculados a los números de solicitud. En algunos casos, esos números son idénticos, mientras que en otros casos serán distintos. El número de solicitud está vinculado a uno o más números de publicación. Las bases de datos de patentes suelen devolver datos basados en números de publicación Sin embargo, a menudo esto es solo una imagen parcial del conjunto de documentos vinculados a una aplicación o conjunto de aplicaciones y sus presentaciones de prioridad subyacentes.
En las filas 10 y 13 de la Tabla 3.2 podemos ver que tenemos un número de publicación. Sin embargo, podemos ver que bajo el Número de miembro de la familia de INPADOC hay varias publicaciones de patentes que no se capturan en el campo del número de publicación. Hay dos razones para esto.
- Una búsqueda de una base de datos de patentes comúnmente devuelve publicaciones de patentes basadas en criterios tales como limitar la búsqueda por jurisdicción. Esto no revela todos los documentos vinculados a una presentación o conjunto de presentaciones en todo el mundo.
- La columna Miembros de la familia INPADOC agrupa publicaciones basadas en una definición particular de una familia de patentes. El número de documentos variará aquí dependiendo de la definición de la familia de patentes utilizada en los datos y si los documentos están deduplicados.
La Tabla 3.3 resume los datos mostrando los recuentos de los diferentes tipos de documentos.
| earlyiest_priority | cuenta_principal | application_count | cuenta_familia |
|---|---|---|---|
| US2016620248F 2016-09-02 | 1 | 1 | 1 |
| US14835329A 2015-08-25 | 1 | 1 | 2 |
| US15174819A 2016-06-06 | 1 | 1 | 1 |
| US2013898275P 2013-10-31 | 2 | 1 | 1 |
| US2015274112P 2015-12-31 | 8 | 18 | 28 |
| US201476360P 2014-11-06 | 7 | 4 | 7 |
La Tabla 3.3 ayuda a aclarar que podemos tratar casos simples (una prioridad o la primera presentación) nos lleva a una solicitud y un miembro de la familia. O bien, podemos estar tratando con un grupo de prioridades que llevan a múltiples aplicaciones y múltiples miembros de la familia. Esto ayuda a aclarar que, al trabajar con datos de patentes, a menudo nos enfrentamos con muchas o muchas relaciones.
En la siguiente sección, avanzaremos progresivamente desde el conteo de documentos de patentes usando números de prioridad y terminaremos usando los conteos de miembros de la familia INPADOC para dilucidar las tendencias de la tecnología relacionada con drones.
3.3 Recuento de prioridad o primeras presentaciones
Cuando se presenta una solicitud de patente por primera vez en cualquier parte del mundo, se convierte en el documento de prioridad o la primera presentación. El uso de este término se basa en el Convenio de París de 1883. El resumen de la OMPI de las disposiciones clave del Convenio de París explica el derecho de prioridad introducido por el Convenio de la siguiente manera.
El Convenio establece el derecho de prioridad en el caso de patentes (y modelos de utilidad donde existan), marcas y diseños industriales. Este derecho significa que, sobre la base de una primera solicitud regular presentada en uno de los Estados contratantes, el solicitante puede, dentro de un cierto período de tiempo (12 meses para patentes y modelos de utilidad; 6 meses para diseños industriales y marcas), aplicar para la protección en cualquiera de los demás Estados contratantes. Estas solicitudes posteriores se considerarán como si se hubieran presentado el mismo día que la primera solicitud. En otras palabras, tendrán prioridad (de ahí la expresión "derecho de prioridad") sobre las solicitudes presentadas por otros durante dicho período de tiempo para la misma invención, modelo de utilidad, marca o diseño industrial. Además, estas aplicaciones posteriores, basadas en la primera aplicación, no se verá afectado por ningún evento que tenga lugar en el intervalo, como la publicación de una invención o la venta de artículos que lleven una marca o que incorporen un diseño industrial. Una de las grandes ventajas prácticas de esta disposición es que los solicitantes que buscan protección en varios países no están obligados a presentar todas sus solicitudes al mismo tiempo, pero tienen 6 o 12 meses para decidir en qué países desean obtener protección y organizarse. Con el debido cuidado los pasos necesarios para asegurar la protección.6
El Manual de la OCDE sobre estadísticas de patentes describe el número de prioridad y la fecha de prioridad de la siguiente manera:
Número de prioridad. Este es el número de solicitud o publicación de la solicitud de prioridad, si corresponde. Permite identificar el país prioritario, reconstruir familias de patentes, etc.
Fecha de prioridad. Esta es la primera fecha de presentación de una solicitud de patente, en cualquier parte del mundo (generalmente en la oficina de patentes nacional del solicitante), para proteger una invención. Es el más cercano a la fecha de invención. (OCDE 2009: 25)
El tema más importante aquí desde la perspectiva de los conteos de patentes es la fecha de prioridad. La Tabla 3.3 anterior reveló que las solicitudes de patentes pueden estar vinculadas a múltiples aplicaciones de prioridad subyacente. La presentación más temprana, como se muestra en la Tabla 3.3 , es la prioridad de París en el sentido de que es la primera de una serie de presentaciones que dan lugar a una invención reivindicada.
En los casos simples como se muestra en las filas 9-11 de la Tabla 3.2, el número de prioridad y el número de solicitud son los mismos. Cuando el número de prioridad y el número de solicitud son los mismos, hemos identificado la prioridad o la primera presentación. Sin embargo, en las filas 12-13 en la Tabla 3.2 vemos casos más complejos que involucran múltiples prioridades. En la fila 5 de la Tabla 3.4 vemos un caso común en el que una presentación a nivel nacional da lugar a una presentación internacional en virtud del Tratado de Cooperación en materia de Patentes que lleva a una solicitud en otro país. En el resto de esta sección veremos una serie de ejemplos.
1. Presentación nacional a presentación internacional
Primero veamos el ejemplo en la fila 5 de la Tabla 3.2 .
| número de prioridad | Numero de aplicacion | número de publicación | inpadoc_family_members |
|---|---|---|---|
| US2016578323F 2016-09-20 | US2016578323F 2016-09-20 | USD801224S1 | N / A |
| US15360203A 2016-11-23 | US15360203A 2016-11-23 | US9807726B1 | N / A |
| US62133061P 2015-03-13 | US15069675A 2016-03-14 | US9804596B1 | N / A |
| US14622134A 2015-02-13 | US14622134A 2015-02-13 | US9802728B1 | N / A |
| JP2015122335A 2015-06-17; WO2016JP67809A 2016-06-15 |
US15322008A 2016-12-23 | US9802691B2 | N / A |
Podemos ver en la fila 5 que JP2015122335A 2015-06-17enumera un segundo número de prioridad para una presentación del Tratado de Cooperación en materia de Patentes WO2016JP67809A 2016-06-15. A primera vista, esto lleva a la solicitud de patente estadounidense US15322008A 2016-12-23que se publica como US9802691B2para a Boyant Aerial Vehicle. Sin embargo, cuando se trabaja con números de prioridad, generalmente nos encontramos con varias aplicaciones que surgen de las prioridades. La tabla 3.5 muestra los recuentos de las prioridades y aplicaciones vinculadas a JP2015122335A 2015-06-17.
| earlyiest_priority | cuenta_principal | application_count |
|---|---|---|
| JP2015122335A 2015-06-17 | 2 | 4 |
El segundo número de prioridad es el Tratado de Cooperación de Patentes WO2016JP67809A 2016-06-15.
La Tabla 3.6 muestra la secuencia de aplicaciones derivadas de las dos prioridades y la familia de patentes INPADOC.
Tabla 3.6: Solicitudes de patente derivadas de JP2015122335A con solicitud PCT WO2016JP67809A
| número de prioridad | Numero de aplicacion | número de publicación | inpadoc_family_members |
| JP2015122335A 2015-06-17 | US15322008A 2016-12-23 | US9802691B2 | N / A |
| JP2015122335A 2015-06-17 | EP2016811654A 2016-06-15 | EP3150483A1 | EP3150483A1 20170405;EP3150483A4 20170920;JP05875093B1 20160302;JP2017007411A 20170112;US20170137104A1 20170518;WO2016204180A1 20161222 |
| JP2015122335A 2015-06-17 | WO2016JP67809A 2016-06-15 | WO2016204180A1 | EP3150483A1 20170405;EP3150483A4 20170920;JP05875093B1 20160302;JP2017007411A 20170112;US20170137104A1 20170518;WO2016204180A1 20161222 |
| JP2015122335A 2015-06-17 | JP2015122335A 2015-06-17 | JP05875093B1 | EP3150483A1 20170405;EP3150483A4 20170920;JP05875093B1 20160302;JP2017007411A 20170112;US20170137104A1 20170518;WO2016204180A1 20161222 |
El primer punto a destacar es que la solicitud de prioridad japonesa se JP2015122335A 2015-06-17convierte en la solicitud JP2015122335A 2015-06-17 y luego se publica como una solicitud de patente en Japón a partir JP2017007411A 20170112de enero de 2017 (primer nivel de publicación) y también como una patente otorgada JP05875093B1 20160302. 7
Sin embargo, la solicitud del Tratado de Cooperación en materia de Patentes WO2016JP67809A 2016-06-15presentada un año después activa solicitudes (en la misma fecha) en los Estados Unidos y en la Oficina Europea de Patentes.
El número de solicitud US15322008A 2016-12-23se publica en mayo de 2017 como US20170137104A1 20170518(primer nivel de publicación) y en el segundo nivel de publicación como US9802691B2.
La solicitud europea EP2016811654A 2016-06-15se publica como EP3150483A1 20170405(primer nivel de publicación con el informe de búsqueda) y como EP3150483A4 20170920con un informe de búsqueda complementario.
Tenga en cuenta que la entrada de la base de datos para los miembros de la familia inpadoc para la solicitud de los Estados Unidos está en blanco (NA significa No disponible) que indica que este registro no se ha actualizado o actualizado correctamente. Una vista actualizada de la familia de patentes está disponible en esp @ cenet e incluye los registros de EE. UU. Y la actividad de patentes más reciente.
Los datos de prioridad en este caso reflejan la decisión tomada por el solicitante sobre la ruta de presentación para buscar la protección en otros países en este caso, Estados Unidos utilizando el Tratado de Cooperación en materia de Patentes. El Tratado de Cooperación en materia de Patentes tiene la ventaja de prolongar el tiempo que disfrutan los solicitantes antes de decidir dónde buscar la protección, desde los 12 meses en virtud del Convenio de París hasta los 30 meses . Los solicitantes también disfrutan de costos reducidos en comparación con el Convenio de París debido a que se presenta una solicitud única que luego puede ser sometida a consideración en otros Estados contratantes.
Tenga en cuenta que la ruta de archivo se puede detectar en el número de prioridad WO2016JP67809A 2016-06-15que contiene el código de país JP como parte del número de solicitud. Es habitual que la lista de números de prioridades siga una secuencia en la que el primer número de prioridad que figura en un documento sea el más temprano, seguido de las aplicaciones posteriores. 8
Como este ejemplo deja en claro cuando se trabaja con datos de patentes, normalmente seguimos un patrón que consiste en:
número de prioridad (el más antiguo)> número de solicitud> publicaciones (bajo diferentes definiciones de familia)
En cada paso se multiplican las publicaciones asociadas a las presentaciones originales.
En este caso, estamos observando la ruta de presentación distintiva que surge de una presentación de prioridad única. La ruta de presentación no tiene nada que ver con la invención per se . Sin embargo, un ejemplo más complejo revela que las invenciones pueden surgir de múltiples invenciones reivindicadas.
2. Invenciones múltiples
Hemos visto anteriormente que en algunos casos las solicitudes de patentes involucran múltiples números de prioridad. La mayoría seguirá el patrón identificado anteriormente. Sin embargo, en algunas áreas tecnológicas, especialmente aquellas relacionadas con la informática, los números de prioridad múltiple pueden ser bastante comunes. En el caso del conjunto de datos de drones, una sola aplicación US14815121A 2015-07-31enumera nada menos que 146 prioridades y ha dado lugar, en el momento de la redacción, a una familia de patentes de INPADOC que consta de 340 publicaciones. Este ejemplo se refiere a Wireless Power System for an Electronic Display with Associated Impedence Matching Network. Se puede identificar en esp @ cenet usando el número de publicación US2015357831A1y se presenta un resumen en la Tabla 3.7 .
| prioridad_país | norte |
|---|---|
| AU | 1 |
| TW | 1 |
| NOSOTROS | 144 |
La Tabla 3.7 revela que la mayoría de las prioridades son las prioridades domésticas de los Estados Unidos (144) con dos prioridades extranjeras en la forma de Australia y Taiwán.
La presentación de prioridad más temprana que figura en el conjunto de prioridades es US2007647705A 2007-12-28la más reciente en 2017, lo que significa que las solicitudes subyacentes vinculadas a esta solicitud se extendieron durante casi una década. De las 143 prioridades vinculadas a la aplicación que se originan en los Estados Unidos, 107 llevan el código de clase A y 36 contienen el código de clase P para una aplicación provisional. Por lo tanto, este parece ser un caso dominado por las solicitudes provisionales de los EE. UU. Y también llamadas de continuación , continuación en parte y divisional .
Las solicitudes provisionales son un tipo común de solicitud de patente en los Estados Unidos donde un solicitante puede presentar y reclamar prioridad a lo que efectivamente es un resumen de una solicitud completa que no contiene reclamaciones de patentes. Estas solicitudes sirven para establecer una fecha de prioridad temprana, pero esto no tendrá efecto hasta que se presente una solicitud real. No se publican solicitudes provisionales. Los detalles de los procedimientos para estos tipos de solicitudes de patentes se encuentran en el "Manual de Procedimiento de Examen de Patentes (MPEP) de la USPTO".
En los Estados Unidos, los solicitantes también están autorizados a presentar la continuación y la continuación en las solicitudes de piezas. En el caso de las continuaciones, el solicitante agrega nuevas reclamaciones que reclaman prioridad a la solicitud presentada anteriormente. En el caso de la continuación en parte, estas aplicaciones agregan un nuevo tema centrado en las mejoras a la aplicación original. Las solicitudes divisionales reclaman prioridad a la aplicación original pero reclaman nuevos inventos distintos en lugar de agregar nuevos reclamos o asunto. Las aplicaciones divisionales a menudo surgen cuando el examinador determina que una aplicación contiene más de un invento.
El uso de la continuación y la continuación en aplicaciones parciales en los Estados Unidos ha sido un foco importante de debate y crítica (Hegde, Mowery y Graham 2007 ) . Como Dechezlepretre et. Alabama. han destacado recientemente:
"A nivel nacional o regional, los solicitantes pueden a su vez utilizar segundas solicitudes nacionales, incluidas las solicitudes divisionales y continuas, para retrasar una concesión de patente. Al presentar una solicitud divisional mientras la solicitud principal aún está pendiente, los solicitantes pueden obtener una segunda (o posiblemente más) patente (s) divisional (es) otorgada más adelante y, mientras tanto, mantener cierta incertidumbre sobre las reclamaciones. En el sistema de patentes de EE. UU., Las continuaciones y las continuaciones en parte se pueden presentar después del examen y apuntan precisamente a agregar más reclamaciones a una patente (Hegde et al. 2009). La presentación de una primera solicitud con reivindicaciones limitadas permite, por lo tanto, que el solicitante obtenga varias patentes sobre la misma invención, ampliando así gradualmente el alcance general de las reivindicaciones e incluso, en el caso de las continuaciones en parte, la duración de la patente. familia."(Dechezleprêtre, Ménière y Mohnen 2017 , en 802)
Si bien los casos en los que se discutió anteriormente son sencillos cuando se trata de un número de prioridad, cuando se enfoca en las solicitudes de continuación en los Estados Unidos, la pregunta que surge aquí es ¿qué se debe contar?
Habiendo comprendido algunos de los problemas potenciales involucrados en la preparación para contar datos de patentes, ahora pasamos a los métodos para contar aplicaciones prioritarias.
URL: http://www.cyta.com.ar/biblioteca/bddoc/bdlibros/manual_analisis_patentes/manual_analisis_patentes.html